

Editor’s note: This is the sixth (and final) in a series of posts from the team that built the 10k Apart contest site, exploring the process of building for interoperability, accessibility, and progressive enhancement in less than 10kB.
In the previous post in this series, I did a deep dive into many of the JavaScript enhancements available to visitors to the 10k Apart site. It was a significant read and if you made it through the whole thing, I commend you.
Once all of the front-end code was basically done, it was time to turn our attention toward compressing the heck out to it. GZip would be there to help us, certainly, but we could do more… a lot more. In this post, Antón Molleda, David García, and I will discuss workflow, server architecture, server-side compression strategies, and some other random dev-ops stuff that might interest you.
How do you manage compression & minification?
As I’ve mentioned a few times in this series, I’m a fan of task runners. If you’re unfamiliar, a task runner is a program that automates repetitive tasks. Ant and Rake are popular tools for doing this sort of automation, as are shell scripts. Within the web world, the ones you see discussed most often are Grunt and Gulp. I wouldn’t presume to know the best option for you, your team, or your project, but for the 10k Apart site I used Gulp.
I’ll start with a simple example, the Gulp task I used for handling the HTML:
| var gulp = require('gulp'), | |
| htmlmin = require('gulp-htmlmin'), | |
| rename = require('gulp-rename'), | |
| notify = require('gulp-notify'), | |
| mustache = require('gulp-mustache'), | |
| mustache_vars = require('../../source/data/mustache_vars.json'); | |
| gulp.task('html', function() { | |
| var source = './source/templates/*.mustache', | |
| destination = './deploy', | |
| htmlmin_config = { | |
| removeComments: true, | |
| collapseWhitespace: true | |
| }; | |
| return gulp.src(source) | |
| .pipe(mustache(mustache_vars,{},{})) | |
| .pipe(htmlmin(htmlmin_config)) | |
| .pipe(rename({extname: '.html'})) | |
| .pipe(gulp.dest(destination)) | |
| .pipe(notify({ message: 'HTML built & minified' })); | |
| }); |
In order to streamline the modularization of my HTML, I used Mustache tempting, partials, and such. That meant that the actual HTML needed to be compiled. Antón will discuss why we opted to compile the code before it went through our back-end system in a moment, so I’ll leave that to him. Suffice to say, most of our pages are static, so it made more sense to assemble them early. This Gulp task does that. Here’s a breakdown of what’s happening:
- Lines 1–6: These are the dependencies for this Gulp task.
- Line 8: This defines the task name. In this case “html”, allowing me to type
gulp htmlon the command line to run the task. - Lines 9–10: These lines define the path to collect the Mustache templates from (
source) and the output location for the HTML files (destination). - Lines 11–14: This is a configuration object for
gulp-htmlminthat tells it to remove all comments and whitespace. - Line 16: This collects the files from the
sourcedirectory and pipes them into the Gulp process. - Line 17: This is where the Mustache variables are dropped into the templates.
- Line 18: This is the minification step, using
gulp-htmlmin. - Lines 19–20: This is where each file is renamed to have a “.html” extension and dropped in the
destinationfolder. - Line 21: This let’s me know the task is complete.
This is probably one of the more simple Gulp tasks I’m using in the project, but the end result is exactly what I wanted: minified HTML compiled from a set of modular templates.
Fair warning: The next Gulp tasks you’ll see involve quite a few more steps.
How did you optimize the CSS?
As I mentioned in the post about the site’s CSS, I’ve written all of the styles using Sass. I also kept everything very modular and organized with the aid of Breakup. Compiling my Sass files into CSS files was actually the first Gulp task I created. Once I had the basic output working well, I began to look for other ways to optimize the generated CSS. Here is the Gulp task that covers all of my CSS:
| var gulp = require('gulp'), | |
| sass = require('gulp-sass'), | |
| autoprefixer = require('gulp-autoprefixer'), | |
| minifycss = require('gulp-clean-css'), | |
| notify = require('gulp-notify'), | |
| rename = require('gulp-rename'), | |
| csso = require('gulp-csso'), | |
| shorthand = require('gulp-shorthand'), | |
| uncss = require('gulp-uncss'); | |
| gulp.task('styles', function() { | |
| var paths = { | |
| sassSrcPath: 'source/scss/**/*.scss', | |
| sassDestPath: 'deploy/c', | |
| sassImportsPath: 'source/scss/' | |
| }; | |
| return gulp.src(paths.sassSrcPath) | |
| .pipe(sass({ | |
| precision: 4 | |
| }).on('error', sass.logError)) | |
| .pipe(autoprefixer('last 2 version')) | |
| .pipe(gulp.dest(paths.sassDestPath)) | |
| .pipe(rename({suffix: '.min'})) | |
| .pipe(shorthand()) | |
| .pipe(uncss({ | |
| html: ['deploy/**/*.html'], | |
| ignore: [ | |
| /.*:{1,2}[\w-]+/, | |
| /clickable/, | |
| /img|svg|input/, | |
| /data\-imaged/, | |
| /microsoft/, | |
| /picture/, | |
| /getActiveMQ/, | |
| /hero/, | |
| /project--preview/, | |
| /crank/, | |
| /\.admin/, | |
| /vote/, | |
| /placeholder/, | |
| /count/, | |
| /cookie\-/, | |
| /\-o\-prefocus/ | |
| ] | |
| })) | |
| .pipe(csso({ | |
| restructure: false // clobbered ::-o-prefocus | |
| })) | |
| .pipe(minifycss({ | |
| shorthandCompacting: false // it was merging rems over pixels | |
| })) | |
| .pipe(gulp.dest(paths.sassDestPath)) | |
| .pipe(notify({ message: 'Styles task complete' })); | |
| }); |
The may be a bit to take in, especially if you’re not familiar with Gulp, but I will break down the important bits for you.
- Lines 20–22: Sass compilation (using
gulp-sass) with a decimal precision of 4. I chose 4 because it gave the greatest consistency across browsers while still being relatively short. - Line 23: Autoprefixer to handle any vendor-prefixing that needed to happen.
- Line 26: Runs
gulp-shorthandto combine any shorthand-able declarations I may have missed. - Lines 27–47: Runs
gulp-uncssagainst my HTML source to weed out unused style rules. I have an array of regular expressions to ignore that cover the JavaScript-injected markup. - Lines 28–50: Runs
gulp-cssoto optimize my CSS. I had to turn off restructuring as it clobbered the::-o-prefocusselector used to target Opera. - Lines 28–50: Runs
gulp-clean-cssto run another set of optimizations (it never hurts, right?).
Unfortunately, clean-css makes some optimizations that break progressive enhancement, so I had to turn off shorthandCompacting. I had several instances where I used CSS’ fault tolerant nature to deliver a modern experience to modern browsers, but also wanted to provide instruction for older browsers too. For instance, consider this bit of code utilizing the lobotomized owl selector:
| * { | |
| margin-top: 0; | |
| margin-bottom: 0; | |
| box-sizing: border-box; | |
| } | |
| * + * { | |
| margin-top: 22px; | |
| margin-top: 1.375rem; | |
| } |
With shorthandCompacting on, the two margin-top declarations in the second rule set be combined:
| * { | |
| margin-top: 0; | |
| margin-bottom: 0; | |
| box-sizing: border-box; | |
| } | |
| * + * { | |
| margin-top: 1.375rem; | |
| } |
It makes complete sense for optimization code to do this, after all I am redefining the value for margin-top in the second declaration. Any modern browser would get that rem value. The problem is that many older browsers (e.g. IE8) don’t understand rem values, but they do understand both of these selectors. That means they would turn off all top & bottom margins (because of the * selector), but would not set the margin-top to any value on all adjacent siblings (* + *). You’d end up with every element running into the previous one and it’s be an unusable mess.
If you used automated tools to compress your code, it’s imperative that you test the compression results to make sure the end result is actually what you intended. Most of these tools go for maximum efficiency and that might not always be desirable.
Are you taking similar steps with the JavaScript?
Using Gulp to optimize the site’s CSS involved a bit of trial and error. In contrast, the JavaScript compilation and compression was pretty straightforward. As I mentioned in the JavaScript post, I organized all of the JavaScript source code in subdirectories and used Gulp to merge the contents of those subdirectories into individual files named after that subdirectory. Let me show you the Gulp task and then I will walk you through it to show how I did that:
| var gulp = require('gulp'), | |
| path = require('path'), | |
| folder = require('gulp-folders'), | |
| gulpIf = require('gulp-if'), | |
| insert = require('gulp-insert'), | |
| concat = require('gulp-concat'), | |
| uglify = require('gulp-uglify'), | |
| notify = require('gulp-notify'), | |
| rename = require('gulp-rename'), | |
| source_folder = 'source/js', | |
| destination_folder = 'deploy/j', | |
| rename_serviceworker = rename({ | |
| dirname: "../" | |
| }); | |
| gulp.task('scripts', folder(source_folder, function(folder){ | |
| function createErrorHandler( name ) | |
| { | |
| return function (err) { | |
| console.error('Error from ' + name + ' in compress task', err.toString()); | |
| }; | |
| } | |
| return gulp.src(path.join(source_folder, folder, '*.js')) | |
| .pipe(concat(folder + '.js')) | |
| .pipe(insert.prepend('(function(window,document){')) | |
| .pipe(insert.append('}(this,this.document));')) | |
| .pipe(insert.transform(function(contents, file){ | |
| // insert a build time variable | |
| var build_time = (new Date()).getTime() + ''; | |
| return contents.replace( '{{BUILD_TIME}}', build_time ); | |
| })) | |
| .pipe(gulpIf(folder=='serviceworker',rename_serviceworker)) | |
| .pipe(gulp.dest(destination_folder)) | |
| .pipe(gulpIf(folder!='serviceworker',uglify().on('error', createErrorHandler('uglify')))) | |
| .pipe(gulpIf(folder!='serviceworker',rename({suffix: '.min'}))) | |
| .pipe(gulpIf(folder!='serviceworker',gulp.dest(destination_folder))) | |
| .pipe(notify({ message: 'Scripts task complete' })); | |
| })); |
Here are some of the highlights:
- Line 16: Here is where we peek into the JavaScript source directory and loop through the subdirectories using
gulp-folders. - Line 25: Here we pipe the
.jsfiles from that subdirectory into the Gulp stream. - Line 26: The files are combined using
gulp-concat. - Lines 27–28: These lines isolate the contents of the concatenated file within a closure to avoid polluting the global scope.
- Lines 29–33: This bit pertains to the Service Worker file I mentioned in the last post. It handles version bumping by inserting the current build time into my Service Worker file.
- Line 34: This renames my Service Worker file so that it sits in the site root as opposed to my normal output folder.
- Lines 36–38: These lines handle minification of the JavaScript files using
gulp-uglify. The Service Worker is excluded because Uglify is (currently) unable to handle the ES2015 code I’m using.
Using this process, I was able to keep my JavaScript code modular and organized and still end up with nicely minified files in the end.
What was the optimization workflow for images?
Images (and other media and document types) tend to be the biggest bandwidth hogs on any webpage. That’s why, as I’ve mentioned in previous posts, I opted to make images optional. They only get added to the page if the user has JavaScript and, in some cases, if the amount of screen real estate available makes it worthwhile to load them.
Even with JavaScript as a gatekeeper, I still optimized the images to the best of my ability. Old-school web designer that I am, I still love Photoshop’s Save for Web tool (File > Export > Save for Web in Photoshop CC 2015.5). Using that tool, I created three export options: 8-bit PNG, 24-bit PNG, and JPEG. I did this because each format excels in with different kinds of images. 8-bit PNGs, for instance, are great when you have a limited color palette and many solid blocks of color. They can also be tuned to reduce the number of colors available (from 1–256), thereby further reducing their size. JPEGs are better for photographs and images that contain color gradients. 24-bit PNGs are like JPEGs (though they are often larger), but they also offer smooth alpha transparency.
I created presets in Photoshop for all three file formats and then used the Save for Web tool to compare the options. What I like about Save for Web is that it lets you easily compare 3 options with your original file. It also provides file size information and approximate download times for various connection speeds. All of this is incredibly handy when you are looking to wring every extraneous bit from your project.
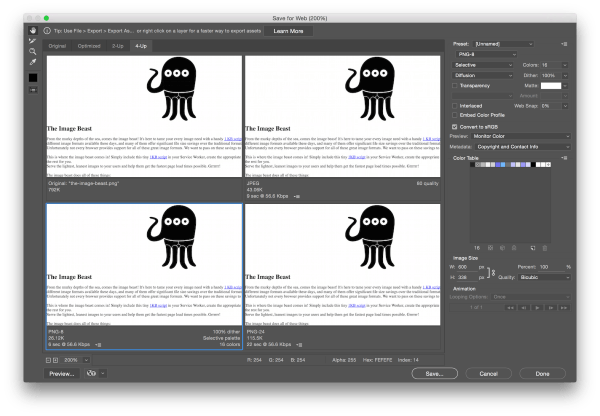
Here’s an example of the Save for Web tool in Photoshop, comparing the three different image output options with the original.Most of the project screenshots worked best as 8-bit PNGs. The judge images worked best as JPGs. But my optimizations did not stop there.
For the judge images, I used a nifty trick I learned from Jeremy Keith: You blur everything but the person’s face. Not sure what I’m talking about? Compare these two shots:

On the left is the original photo of Lara Hogan, which clocks in at 22kB as an 80% quality JPEG. On the right is the treated photo, which clocks in at 16kB as an 80% quality JPEG. As humans are, with some exceptions, wired to focus on facial features, most of you probably didn’t notice much of a difference between the two photos on first blush. And since we rarely sit there and ponder photos on the Web, especially headshots, the loss of superfluous detail is absolutely worth it for the reduced file size.
If you’re wondering how I did it, here are the steps in Photoshop:
- Duplicate the photo layer.
- Select the photo subject’s face. Typically I use the Elliptical Marquee Tool (M).
- Feather the selection by 5px (Select > Modify > Feather or Shift+F6).
- Select the top layer.
- Apply a Layer Mask (hit the Layer Mask button in the Layers Palette or choose Layer > Layer Mask > Reveal Selection).
- Select the original layer.
- Apply a Gaussian Blur (Filters > Blur > Gaussian Blur). I typically like a radius of 1.0, but you can choose the level of blur you want to apply. Keep in mind: more blur generally means a smaller file.
Then I use Save for Web and tweak the settings for the JPEG to get it as small as possible without introducing noise or distortion.
It’s also worth noting that I opted to make all of the judge images black & white which also makes them much smaller than color photos. If you want to go greyscale, please don’t fall into the trap of only doing this client-side using CSS filters unless you plan on using the color image in some way too. A black & white image is gonna be much smaller than a color version you turn black & white on the client side and it doesn’t require additional code to make it greyscale.
Once I have my hand-optimized images, I run them through ImageOptim. I even added this set into a Gulp task for images (which I’ll get to in a moment). ImageOptim can further reduce the size of JPEGs. I think it does so through some sort of dark magic. Regardless, ImageOptim manages to shave nearly 8% off of the size of my already optimized JPEG, getting it down to 14.6kB on disk. That’s pretty good and it’s way better than the original 22kB file which, incidentally, ImageOptim can only reduce by another 5.6% to 21kB.
Now JPEGs are great and all, but there’s another relatively well-supported image format out there that can achieve better image compression: WebP. I mentioned WebP in the JavaScript post and highlighted how we can use the picture element to serve WebP to browsers that support it, and fall back to JPEG in browsers that don’t. If you missed that, I recommend going back and reading it.
What’s cool about WebP is that the file sizes are typically much smaller than their JPEG or PNG equivalents. The amount varies by image (and in some cases can be larger), but the WebP created from optimized JPEG version of Lara’s photo clocks in at only 7kB on disk as opposed to 15kB. It’s less than half the size!
There are online converters for WebP, but I opted to use Gulp to handle this for me. Here’s the Gulp task I use for all of the image processing:
| var gulp = require('gulp'), | |
| newer = require('gulp-newer'), | |
| imagemin = require('gulp-imagemin'), | |
| notify = require('gulp-notify'), | |
| webp = require('gulp-webp'); | |
| gulp.task('images', function() { | |
| var source = './source/images', | |
| destination = './deploy/i'; | |
| // Optimize & move | |
| gulp.src( source + '/**/*.{jpg,png,svg,gif}') | |
| // Only new stuff | |
| .pipe(newer(destination)) | |
| // Optimize | |
| .pipe(imagemin()) | |
| // Copy | |
| .pipe(gulp.dest(destination)) | |
| ; | |
| // Make WebP versions or PNG & JPG | |
| gulp.src(source + '/**/*.{jpg,png}') | |
| // Only new stuff | |
| .pipe(newer(destination)) | |
| // WebP | |
| .pipe(webp()) | |
| // Publish | |
| .pipe(gulp.dest(destination)) | |
| ; | |
| return true; | |
| }); |
This task has two parts two it. In the first pass, it optimizes GIF, JPEG, PNG, and SVG files using gulp-imagemin (which is, itself, a wrapper around gifsicle, jpegtran, optipng, and svgo) and copies the compressed files from the source folder to the deploy folder. In the second pass, it grabs all of the JPEG and PNG files and converts them to WebP using gulp-webp, dropping the files in that same destination folder. And all I have to do it run gulp images on the command line and I’m good.
Can you automate these automations?
One of the great features of most of the task runners is the ability to “watch” directories for changes and then take action. I created the following as my watch task:
| var gulp = require('gulp'); | |
| gulp.task('watch', function() { | |
| gulp.watch('source/scss/**', ['styles']); | |
| gulp.watch('source/js/**', ['scripts']); | |
| gulp.watch('source/images/**', ['images']); | |
| gulp.watch('source/templates/**', ['html']); | |
| gulp.watch('source/data/**', ['html']); | |
| gulp.watch('source/webconfigs/**/*', ['webconfigs']); | |
| gulp.watch('deploy/*.html', ['a11y']); | |
| }); |
This tasks sets a number of “watchers” that look for changes to files within the identified directory (and, optionally, its subdirectories) and then run specific tasks when a change is detected. On line 4 of this file, Gulp is watching for changes to any files within source/scss (including files within its subdirectories) and then triggers the “styles” task to run when a change is detected. All I have to do is type gulp watch on the command line within this project and then I can go about doing my work. Gulp will re-build, optimize, minify, and compress the files as necessary.
Before moving on, I do want to point out one other neat automation I added in here. It’s that last watcher. It looks for changes to the HTML files staged for deployment and runs a basic accessibility audit on them using gulp-a11y. It’s not an exhaustive audit by any means, but it helpful for catching silly mistakes and oversights.
Ok, enough about Gulp. I’m gonna hand it over to Antón to talk a little bit about the server architecture now. Take it away Antón!
What’s going on behind the scenes?
The 10K Apart server side is written in Node and, like the projects entered in the contest, is hosted in Azure. Node on Windows? Yes. And it enables us to do some pretty cool things that I’ll get to shortly.
The website itself is fairly simple: We have a few pages (most of them static) with a couple forms that create items in Azure’s noSQL Table Storage. We use Express to handle the routing and Handlebars for templating. So far, nothing out of the ordinary. The interesting part comes when serving the static pages and assets.
One of our goals was to have the minimum possible footprint. In most cases this means optimizing the images, and then minifying JS, CSS, and even the HTML. We wanted to save as many bytes as possible so we knew we had to take even more control over those assets. For that reason, we decided to compress the assets ourselves instead of using the automatic compression algorithms used by IIS. Doing that gave us the opportunity to use other formats not yet supported out of the box by the server, such as Brotli. But I’m getting ahead of myself.
We start by optimizing and compressing all of our assets ahead of time. Aaron discussed those in the previous sections. Once we had the minified files, we ran them through a multi-step process to compress them. The Gulp pipeline looks like this:
- Create WebP images from PNG & JPEG source files,
- Optimize all images (including SVGs),
- Concatenate & minify JavaScript,
- Generate, optimize & minify CSS,
- Generate & minify static pages,
- Zopfli-fy assets (Gzip),
- Brotli-fy assets, and finally
- Publish!
With the minified & compressed source files created, we needed a way to ensure we served the right files to each browser.
It’s generally agreed that Node isn’t the best option for serving static files; if possible, you want to delegate that task to other technology. Thankfully, IIS allows us to do this pretty easily using a web.config file. Configuring IIS to serve pre-compressed content (and in two different formats), however, can be a bit tricky. Here’s how we did it:
| <?xml version="1.0"?> | |
| <configuration> | |
| <system.web> | |
| <compilation debug="false" targetFramework="4.0" /> | |
| </system.web> | |
| <system.webServer> | |
| <urlCompression doStaticCompression="true" doDynamicCompression="true" dynamicCompressionBeforeCache="false" /> | |
| <!-- add a mime type for br, otherwise we get 404 --> | |
| <staticContent> | |
| <remove fileExtension=".br" /> | |
| <mimeMap fileExtension=".br" mimeType="application/brotli" /> | |
| </staticContent> | |
| <rewrite> | |
| <rewriteMaps> | |
| <!-- pre-compressed files will be suffixed with br or gz --> | |
| <!-- map of correct mime types to be restored --> | |
| <rewriteMap name="CompressedExtensions" defaultValue=""> | |
| <add key="js.gz" value="application/javascript" /> | |
| <add key="css.gz" value="text/css" /> | |
| <add key="js.br" value="application/javascript" /> | |
| <add key="css.br" value="text/css" /> | |
| </rewriteMap> | |
| </rewriteMaps> | |
| <rules> | |
| <rule name="ServerPreCompressedBrotli" stopProcessing="true"> | |
| <match url="^(.*/)?(.*?)\.(css|js)([?#].*)?$" /> | |
| <conditions> | |
| <!-- client accepts brotli --> | |
| <add input="{HTTP_ACCEPT_ENCODING}" pattern="br" negate="false" /> | |
| <!-- pre-compressed brotli file exists --> | |
| <add input="{REQUEST_FILENAME}.br" matchType="IsFile" negate="false" /> | |
| </conditions> | |
| <!-- serve pre-compressed file --> | |
| <action type="Rewrite" url="{R:1}{R:2}.{R:3}.br{R:4}" /> | |
| </rule> | |
| <rule name="ServerPreCompressedZopfli" stopProcessing="true"> | |
| <match url="^(.*/)?(.*?)\.(css|js)([?#].*)?$" /> | |
| <conditions> | |
| <!-- client accepts gzip --> | |
| <add input="{HTTP_ACCEPT_ENCODING}" pattern="gzip" negate="false" /> | |
| <!-- pre-compressed zopfli file exists --> | |
| <add input="{REQUEST_FILENAME}.gz" matchType="IsFile" negate="false" /> | |
| </conditions> | |
| <!-- serve pre-compressed file --> | |
| <action type="Rewrite" url="{R:1}{R:2}.{R:3}.gz{R:4}" /> | |
| </rule> | |
| </rules> | |
| <outboundRules> | |
| <!-- restore the correct mime type --> | |
| <rule name="RestoreMime" enabled="true"> | |
| <match serverVariable="RESPONSE_Content_Type" pattern=".*" /> | |
| <conditions> | |
| <add input="{HTTP_URL}" pattern="\.((?:css|js)\.(gz|br))" /> | |
| <add input="{CompressedExtensions:{C:1}}" pattern="(.+)" /> | |
| </conditions> | |
| <action type="Rewrite" value="{C:3}" /> | |
| </rule> | |
| <rule name="RemoveRangeBrotli" preCondition="PreCompressedBrotli" enabled="false"> | |
| <match serverVariable="RESPONSE_Content_Range" pattern=".*" /> | |
| <action type="Rewrite" value="" /> | |
| </rule> | |
| <rule name="RemoveRangeZopfli" preCondition="PreCompressedZopfli" enabled="false"> | |
| <match serverVariable="RESPONSE_Content_Range" pattern=".*" /> | |
| <action type="Rewrite" value="" /> | |
| </rule> | |
| <!-- indicate response is encoded with brotli --> | |
| <rule name="AddEncodingBrotli" preCondition="PreCompressedBrotli" enabled="true" stopProcessing="true"> | |
| <match serverVariable="RESPONSE_Content_Encoding" pattern=".*" /> | |
| <action type="Rewrite" value="br" /> | |
| </rule> | |
| <!-- indicate response is encoded with gzip --> | |
| <rule name="AddEncodingZopfli" preCondition="PreCompressedZopfli" enabled="true" stopProcessing="true"> | |
| <match serverVariable="RESPONSE_Content_Encoding" pattern=".*" /> | |
| <action type="Rewrite" value="gzip" /> | |
| </rule> | |
| <preConditions> | |
| <preCondition name="PreCompressedZopfli"> | |
| <add input="{HTTP_URL}" pattern="\.((?:css|js)\.gz)" /> | |
| </preCondition> | |
| <preCondition name="PreCompressedBrotli"> | |
| <add input="{HTTP_URL}" pattern="\.((?:css|js)\.br)" /> | |
| </preCondition> | |
| </preConditions> | |
| </outboundRules> | |
| </rewrite> | |
| </system.webServer> | |
| </configuration> |
As you can see, it’s a not a simple solution, but it ensures that IIS serves the right content to every browser. And pre-compressing the static assets ahead of time makes that possible. Sadly, the web.config file only allows us to serve static files like images, JS and CSS. We could also serve the HTML pages directly, but we’d have to include the extension in the URLs and it would have made the file even more complicated—I promise we tried!—so we decided to handle the HTML directly in Node, even when the pages are static.
As I mentioned, we are using Express. In Express, the best way to know what encodings a user agent supports is via req.acceptsEncodings(encoding) (where encoding can be ‘br’, or ‘gz’). We serve the appropriate file based on the response to this query. Additionally, because we don’t want to read from disk on every request, we keep those files in memory. Here’s how we do that:
| var render = function (encoding) { | |
| return function (page, req, res) { | |
| if (encoding && !req.acceptsEncodings(encoding)) { | |
| return false; | |
| } | |
| var content = getContent(page, encoding); | |
| if (content) { | |
| res.set('Content-Encoding', encoding); | |
| res.set('Content-Type', 'text/html'); | |
| res.end(content, encoding ? 'binary' : null); | |
| return true; | |
| } | |
| return false; | |
| }; | |
| }; | |
| var renderers = [ | |
| render('br'), | |
| render('gz'), | |
| render() | |
| ]; | |
| var renderContent = function (page, req, res) { | |
| return _.some(renderers, function (renderer) { | |
| return renderer(page, req, res); | |
| }); | |
| }; | |
| var showPage = function (req, res, next) { | |
| var page = req.params.page; | |
| if (!renderContent(page, req, res)) { | |
| return next({ status: 404 }); | |
| } | |
| }; |
Here’s what’s happening:
- Detect the supported compression format (our preference is Brotli, followed by Gzip, then the uncompressed version);
- Check to see if we have the requested file in memory;
- If we do, we send it (as binary, if compressed);
- If we don’t, we read it (as binary, if compressed), send it to the browser, and store the file it in memory to respond to future requests.
Obviously, we wanted to make sure all this work was worth it so we run some tests to see how the different files compare between the different formats:
| File | flat (bytes) | zopfli (bytes) | zopfli savings | brotli (bytes) | brotli savings | Delta |
|---|---|---|---|---|---|---|
| 404.html | 2269 | 966 | 57% | 736 | 68% | 10% |
| 500.html | 2254 | 970 | 57% | 703 | 69% | 12% |
| admin.html | 2359 | 906 | 62% | 692 | 71% | 9% |
| colophon.html | 4771 | 1906 | 60% | 1499 | 69% | 9% |
| enter.html | 2692 | 1061 | 61% | 769 | 71% | 11% |
| faq.html | 9713 | 3565 | 63% | 2808 | 71% | 8% |
| favicon.ico | 67646 | 2975 | 96% | 2421 | 96% | 1% |
| gallery.html | 2475 | 939 | 62% | 701 | 72% | 10% |
| hi.html | 3402 | 1328 | 61% | 985 | 71% | 10% |
| index.html | 6395 | 2203 | 66% | 1711 | 73% | 8% |
| legal.html | 20296 | 6954 | 66% | 5560 | 73% | 7% |
| patterns.html | 8226 | 2105 | 74% | 1622 | 80% | 6% |
| project.html | 1373 | 937 | 32% | 716 | 48% | 16% |
| enter.min.js | 964 | 468 | 51% | 378 | 61% | 9% |
| form-saver.min.js | 1391 | 650 | 53% | 543 | 61% | 8% |
| gallery.min.js | 792 | 471 | 41% | 359 | 55% | 14% |
| hero.min.js | 2110 | 797 | 62% | 705 | 67% | 4% |
| home.min.js | 1318 | 694 | 47% | 558 | 58% | 10% |
| main.min.js | 2915 | 1304 | 55% | 1103 | 62% | 7% |
| project.min.js | 4450 | 1930 | 57% | 1775 | 60% | 3% |
| update.min.js | 1177 | 659 | 44% | 552 | 53% | 9% |
| a.min.css | 7637 | 1917 | 75% | 1664 | 78% | 3% |
| admin.min.css | 810 | 407 | 50% | 296 | 63% | 14% |
| d.min.css | 13182 | 3040 | 77% | 2722 | 79% | 2% |
| 59.51% | 67.85% | 8.33% |
It’s worth noting that the average difference between Brotli and Zopfli, in our case, is 8.33%. That number is far from the 20%–26% savings touted when Brotli was announced. Not sure why we have this difference (maybe because the files are already small to begin with?) but in this contest every byte counts, so we’ll take it!
Thanks Antón! Now I’m gonna pass the torch to David so he can discuss some of the DevOps stuff going on behind the scenes.
How do you handle project deployments?
All submissions to the 10k Apart contest are hosted on Azure, just like the contest site itself. Manually deploying every one of those entries would be a painful, time-consuming process, so we decided to create some PowerShell scripts to automate the process as bit. There’s still a lot of manual processing that happens with each entry, but this speeds up the repetitive stuff.
If you’re unfamiliar, PowerShell was originally created as a Windows-only automation platform and scripting language. Recently, however, PowerShell has opened up and is available for Ubuntu, CentOS, and even macOS.
Here’s the rough process for deploying a project:
- Read the information for the project we want to deploy,
- Configure a deployment with the project’s information,
- Deploy the project, and finally
- Update project status to “deployed”.
As Antón mentioned, our database is held in Azure Table Storage, so the PowerShell script just needs to look for the next project we’ve flagged as “ready to deploy”:
| $Table = Get-AzureStorageTable -Name $tableName -Context $Context | |
| $query = New-Object Microsoft.WindowsAzure.Storage.Table.TableQuery | |
| $query.FilterString = "status eq '${status}'" | |
| $entities = $Table.CloudTable.ExecuteQuery($query) |
The $status we are looking for in this particular case is “accepted”. Once we have the next entity to deploy, we configure the deployment using a template:
| $TemplateFile = Join-Path (pwd) "templates/deployment.json" | |
| $parameters = @{ | |
| "hostingPlanName" = "${siteName}-hostPlan"; | |
| "repo" = $repo; | |
| "siteName" = $siteName; | |
| "python" = $python; | |
| } |
We fill in the template with a unique site name, the path to the GitHub repository, a hosting plan name (which is used for billing purposes), and the python version if applicable. Once we have the configuration for the deploy, we deploy the project:
| $deploy = New-AzureRmResourceGroupDeployment -ResourceGroupName $(Get-ResourceGroupName) ` | |
| -TemplateFile $TemplateFile ` | |
| -TemplateParameterObject $parameters |
Finally, we update the project status ($status) to “deployed”:
| $Table = Get-AzureStorageTable -Name $tableName -Context $Context | |
| $entity = New-Object -TypeName Microsoft.WindowsAzure.Storage.Table.DynamicTableEntity -ArgumentList $partitionKey, $rowKey | |
| $entity.Properties.Add("status", $status) | |
| $Table.CloudTable.Execute([Microsoft.WindowsAzure.Storage.Table.TableOperation]::InsertOrMerge(($entity))) |
This setup allows us to easily handle deployments based on each project’s unique configuration needs—Node with NPM, PHP with Composer, and so on. After getting some feedback from you, we even took things a step further and enabled you to inject environment variables so you would not have to worry about putting private API keys in your public GitHub repositories. With the whole process governed by PowerShell like this, it becomes easy to make upgrades like this.
What exactly are “deployment templates”?
To automate all of the deployment processes, we are using something called deployment templates. These files define the deployment and configuration for each server type supported by the contest. Having the configurations stored in a file makes it easy to update them and lets us keep the deployment process relatively stack-agnostic. The Azure team has gathered an excellent collection of deployment templates on GitHub.
Our goal for the project was to create a new Azure instance for each project, using its GitHub repository as the source for the deployment. The contest supports many different server stacks: static (for non-dynamic projects), Node, Python, PHP and .NET Core. We were able to support all of these using 3 templates.
It may seem strange to you that I’m saying this, but two of the templates relate to PHP: The first is for PHP projects that use Composer for dependency management. Composer is not supported out of the box on Azure (yet!), so we’ve configured the template to use this site extension to take care of it. Unfortunately, if a PHP project doesn’t use Composer the deployment will not work, so we needed a second PHP template to handle that case (and, of course, we needed to detect if a PHP project uses Composer!).
The third and final template is for the rest of server types. The only tricky bit is that we leave Python disabled by default and activate it only if the project needs it, otherwise .Net and Node projects won’t work.
This approach has worked really well for managing dozens upon dozens of deployments and allows us to streamline the deployment process quite a bit.
Great stuff David! As you can see, there’s a lot of interesting stuff going on behind the scenes of the 10k Apart contest too.
What did we learn?
This post was a little far-ranging, so here’s a little summary of the stuff we covered:
- Script repetitive tasks — There are a ton of options out there to help automate the stuff you really don’t want to be doing by hand… find one that works for you;
- Double check the output — If you’re automating the compression or minification of CSS and JavaScript, don’t assume the end result is what you intended;
- Optimize and then optimize some more — Sometimes it pays to take multiple runs at optimization (as I did with the images) because every piece of software optimizes differently;
- Serve the smallest files you can — Gzip is not the end-all-be-all, keep an eye out for opportunities to use other well-supported compression algorithms like Brotli.
- Standardize your deployments — You never know when you might need to spin up another server… using deployment templates or other tools like Vagrant, Chef, and Puppet can help keep everything in sync.
Where to next?
That’s it. I think we’ve pretty much covered every aspect of this project. Hopefully you’ve learned some interesting approaches and techniques along the way. Maybe you can even apply some of this knowledge to your own entry to the contest (hint, hint).
Many thanks to Antón Molleda and David García for sharing a little bit about their contributions to this project and for handling the server side of things so I could focus on the front end. Thanks to everyone else who’s been involved in this project too: Stephanie Stimac, Sarah Drasner, David Storey, Eric Meyer, Jeffrey Zeldman, and Kyle Pflug. And, most of all, thank you for reading about how we made it and for submitting your awesome projects to the contest!
― Aaron Gustafson, Web Standards Advocate