

In Windows 10, speech is front-and-center with the Cortana personal assistant, and the Universal Windows Platform (UWP) gives us several ways to plug into that “Hey, Cortana” experience. But there’s much more that we can do when working with speech from a UWP app and that’s true whether working locally on the device or remotely via the cloud.
In this 3-part series, we will dig in to some of those speech capabilities and show that speech can be both a powerful and a relatively easy addition to an app. This series will look at…
- the basics of getting speech recognized
- how speech recognition can be guided
- how we can synthesize speech
- additional capabilities in the cloud for our UWP apps
In today’s post, we’ll start with the basics.
Just because we can doesn’t always mean we should
Using a “natural” interaction mechanism like speech requires thought and depends on understanding users’ context:
- What are they trying to do?
- What device are they using?
- What does sensor information tell us about their environment?
As an example, delivering navigation directions via speech when users are driving is helpful because their hands and eyes are tied up doing other things. It’s less of a binary decision, though, if the users are walking down their city streets with their devices held at arms’ length—speech might not be what they are looking for in this context.
Context is king, and it’s not easy to always get it right even with a modern device that’s packed with sensors. Consider your scenarios carefully and look at our guidance around these types of interactions before getting started.
Text to speech
Back to the code. Let’s get started by writing a short UWP function in C# that gets some speech from the user and turns it into text:
[code language=”csharp”]
async Task<string> RecordSpeechFromMicrophoneAsync()
{
string recognizedText = string.Empty;
using (SpeechRecognizer recognizer =
new Windows.Media.SpeechRecognition.SpeechRecognizer())
{
await recognizer.CompileConstraintsAsync();
SpeechRecognitionResult result = await recognizer.RecognizeAsync();
if (result.Status == SpeechRecognitionResultStatus.Success)
{
recognizedText = result.Text;
}
}
return (recognizedText);
}
[/code]
Note that the lifetime of the SpeechRecognizer in this snippet is kept very short, but it’s more likely in a real application that we would keep an instance in a member variable and re-use it over time.
If we build this code into an application that has been configured to allow access to the microphone and then say “Hello World,” then the function above runs for approximately 5 seconds before returning the string “hello world.”
What are you listening to?
That snippet above no doubt raises questions. Likely first among these is how the system decided which microphone it should listen to. This decision going to depend on the type of device and the microphones available to it with the widest choice most likely being on a PC where the audio device configuration is used to select the default device as below:
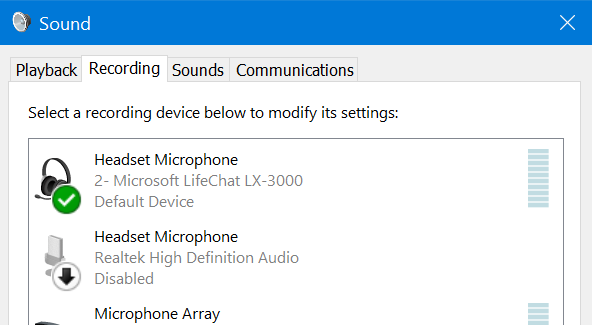
What are you listening for?
Your next question might be around which language the SpeechRecognizer is expecting to come from that microphone, or can it just interpret all the languages of the world in one go?
No, it can’t. That magic still lives in the future right now, so the SpeechRecognizer will use the default language specified in the PC’s system settings:
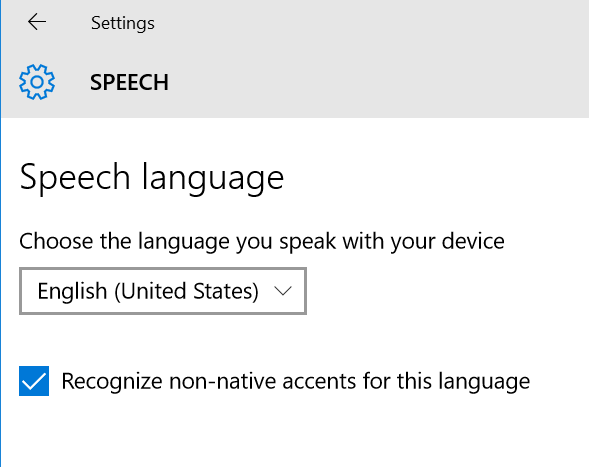
That language is reflected in a static property available from the SpeechRecognizer named SystemSpeechLanguage. Our code then could have constructed the SpeechRecognizer via the equivalent but more explicit snippet:
[code language=”csharp”]
using (SpeechRecognizer recognizer =
new Windows.Media.SpeechRecognition.SpeechRecognizer(
SpeechRecognizer.SystemSpeechLanguage))
[/code]
Our next call after constructing the recognizer was to SpeechRecognizer.CompileConstraintsAsync and yet, curiously, we didn’t have any other code that mentioned these ‘constraints,’ so that perhaps needs a little explanation.
The framework here has applied some sensible defaults for us, but it’s usual to constrain speech recognition and that can be done using a ‘topic’ (a pre-defined grammar) or a ‘grammar’ (a custom grammar).
- Topics:
- Includes dictation, form filling, and web search, which can be further guided by providing hints.
- Grammars:
- A word list – e.g. “fish,” “chips,” “mushy peas.”
- A speech recognition grammar (using the SRGS standard).
- A voice command definition file (as used with Cortana).
We will look at these constraints in more detail in the next article but it is intertwined with language support in the sense that the SpeechRecognizer maintains two lists of supported languages that are dependent upon the language packs installed on the system:
[code language=”csharp”]
// the languages supported for topics (dictation, form filling, etc)
List<Language> languagesForTopics =
SpeechRecognizer.SupportedTopicLanguages.ToList();
// the languages supported for grammars (SRGS, word lists, etc)
List<Language> languagesForGrammars =
SpeechRecognizer.SupportedGrammarLanguages.ToList();
[/code]
Which list you need to check to ensure support will, therefore, depend on which type of constraints you want to apply to the recognition.
How long will you listen for?
Our original code ran for around 5 seconds before returning a result, and it would have done so even if we hadn’t spoken to it at all.
However, if we’d spoken a longer phrase than “Hello World,” that phrase would still have been captured and returned. How is the SpeechRecognizer making these decisions? It comes down to the Timeouts property, which we can tweak:
[code language=”csharp”]
// defaults to 5 seconds
recognizer.Timeouts.InitialSilenceTimeout = TimeSpan.FromSeconds(10);
// defaults to 0.5 seconds
recognizer.Timeouts.EndSilenceTimeout = TimeSpan.FromSeconds(5);
SpeechRecognitionResult result = await recognizer.RecognizeAsync();
[/code]
The behavior is then altered to wait for up to 10 seconds for speech and to wait for 5 seconds after speech, so it’s easy to get this code to run for over 15 seconds by delaying the initial speech.
Does recognition return a “Yes/No” result?
Having got a return value back from the SpeechRecognizer.RecognizeAsync method, our original code only checked a single Status property to check for Success, but there are many Status values that can be returned here, including errors relating to audio quality issues or the language used.
The SpeechRecognitionResult itself can deliver more complex results when working with constraints and can also deliver alternate options along with confidence values. We could add some of this logic into our code such that it builds a formatted string that delivers either a high confidence response or a list of the alternatives when confidence is not quite so high:
[code language=”csharp”]
SpeechRecognitionResult result = await recognizer.RecognizeAsync();
StringBuilder stringBuilder = new StringBuilder();
if (result.Status == SpeechRecognitionResultStatus.Success)
{
if (result.Confidence == SpeechRecognitionConfidence.High)
{
stringBuilder.Append($"We are confident you said ‘{result.Text}’");
}
else
{
IReadOnlyList<SpeechRecognitionResult> alternatives =
result.GetAlternates(3); // max number wanted
foreach (var option in alternatives)
{
stringBuilder.AppendLine(
$"We are {option.RawConfidence * 100:N2}% confident you said ‘{option.Text}’");
}
}
recognizedText = stringBuilder.ToString();
}
[/code]
We have to wait for the complete results to come back?
Our original code might have given the impression that the speech recognition engine is a ‘black box’—we make a call to RecognizeAsync and we wait for it to return with little interaction in the meantime. That might prove a real challenge to keeping a user engaged in an interaction.
To aid with that, the SpeechRecognizer has events for HypothesisGenerated and StateChanged, which we can hook in order to monitor the processing. We can also watch for the RecognitionQualityDegrading event and take action to guide the user. In the snippet below, we’ve attached handlers for the first two events:
[code language=”csharp”]
using (SpeechRecognizer recognizer =
new Windows.Media.SpeechRecognition.SpeechRecognizer())
{
recognizer.HypothesisGenerated += (s, e) =>
{
System.Diagnostics.Debug.WriteLine(
$"Recogniser is thinking about ‘{e.Hypothesis.Text}’");
};
recognizer.StateChanged += (s, e) =>
{
System.Diagnostics.Debug.WriteLine(
$"Recognizer changed state to {e.State}");
};
[/code]
And viewing this output from Visual Studio’s Output window gives something like the following:
[code language=”csharp”]
Recognizer changed state to Capturing
Recognizer changed state to SoundStarted
Recognizer changed state to SpeechDetected
Recogniser is thinking about ‘how’
Recogniser is thinking about ‘hello’
Recogniser is thinking about ‘hello I’
Recogniser is thinking about ‘hello I want to’
Recogniser is thinking about ‘hello I wanted’
Recogniser is thinking about ‘hello I want to see’
Recogniser is thinking about ‘hello I wanted to see what’
Recogniser is thinking about ‘hello I wanted to see what you’
Recogniser is thinking about ‘hello I wanted to see what you can’
Recogniser is thinking about ‘hello I wanted to see what you could’
Recogniser is thinking about ‘hello I wanted to see what you could read’
Recogniser is thinking about ‘hello I wanted to see what you could wreck’
Recogniser is thinking about ‘hello I wanted to see what you could record’
Recogniser is thinking about ‘hello I wanted to see what you could recognize’
Recogniser is thinking about ‘hello I wanted to see what you could recognize as I’
Recogniser is thinking about ‘hello I wanted to see what you could recognize I’m’
…
Recognizer changed state to SoundEnded
Recognizer changed state to Processing
Recognizer changed state to Idle
[/code]
It’s possible to build this into quite a rich UX that shows the user feedback as they are progressing, but don’t necessarily assume that you need to build that UX just yet.
There’s no UX for this?
Our original code example made use of the SpeechRecognizer.RecognizeAsync method, but the class has a sibling method called SpeechRecognizer.RecognizeWithUIAsync, which displays standard recognition UX for the device family and which can be controlled via the UIOptions property.
In the code snippet below, we tweak all the available options:
[code language=”csharp”]
recognizer.UIOptions.AudiblePrompt = "Say your bank account number";
recognizer.UIOptions.ExampleText = "for example ‘12349876’";
recognizer.UIOptions.IsReadBackEnabled = true;
recognizer.UIOptions.ShowConfirmation = true;
SpeechRecognitionResult result = await recognizer.RecognizeWithUIAsync();
[/code]
And the UI displayed reflects our choices:
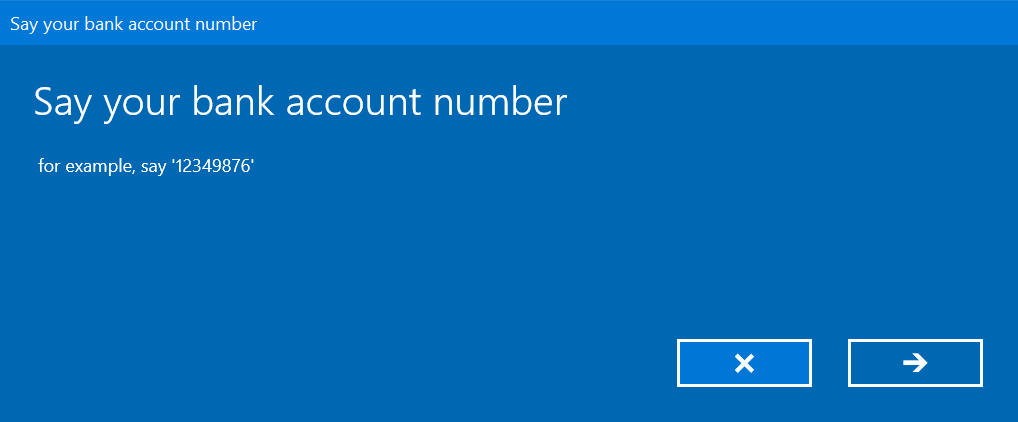
It is giving the user the ability to cancel out or complete the flow, showing the speech as it is hypothesized, and also offering the user a chance to retry:

Along with a confirmation that has an audible prompt, it comes with another option to cancel the flow:

For fairly ‘standard’ scenarios, there’s an opportunity to make use of what has already been built into the framework here and avoid having to do that custom work and, naturally, that’s true across Windows device families.
Going beyond a single sentence of speech
In some scenarios, you might want to put an application into a ‘listening’ mode and have it continuously recognizing speech without having to call the RecognizeAsync method repeatedly.
The SpeechRecognizer calls this a “continuous recognition session,” and it’s reflected by the property SpeechRecognizer.ContinuousRecognitionSession, which comes with its own asynchronous methods to Start, Stop, Pause, Resume, and Cancel, as well as its own AutoStopSilenceTimeout for controlling when it should give up after not hearing the user for a while.
A session like this will generate a sequence of results (the ResultGenerated event fires) and can be configured to pause for each one or keep on running. The results produced follow the pattern that we’ve already seen, and hypotheses are also generated as part of the process. When the complete session ends, the Completed event fires.
Bringing it together
Let’s bring this all together. As an example, perhaps we want a class that records lottery number choices. Here’s a simple example of a class that might do something like that:
[code language=”csharp”]
class LotteryNumberRecognizer : IDisposable
{
private class LotteryOptions
{
public int Min { get; set; }
public int Max { get; set; }
public int Count { get; set; }
public int? Parse(string text)
{
int? value = null;
int temporaryValue = 0;
if (int.TryParse(text.Trim(), out temporaryValue) &&
(temporaryValue >= this.Min) &&
(temporaryValue <= this.Max))
{
value = temporaryValue;
}
return (value);
}
}
public LotteryNumberRecognizer(int numberCount = 6, int min = 1, int max = 59)
{
this.lotteryOptions = new LotteryOptions()
{
Min = min,
Max = max,
Count = numberCount
};
}
public void Dispose()
{
this.recognizer?.Dispose();
this.recognizer = null;
}
public async Task<IReadOnlyList<int>> GetNumbersFromUserAsync()
{
this.resultsList = new List<int>();
this.taskCompletion = new TaskCompletionSource<bool>();
await this.CreateRecognizerAsync();
await this.recognizer.ContinuousRecognitionSession.StartAsync(
SpeechContinuousRecognitionMode.Default);
bool succeeded = await this.taskCompletion.Task;
if (!succeeded)
{
throw new TimeoutException(
"Failed gathering data, for brevity assuming it’s a timeout");
}
return (this.resultsList.AsReadOnly());
}
async Task CreateRecognizerAsync()
{
if (this.recognizer == null)
{
this.recognizer = new SpeechRecognizer();
this.recognizer.Timeouts.EndSilenceTimeout = TimeSpan.FromMilliseconds(250);
this.recognizer.Timeouts.InitialSilenceTimeout = TimeSpan.FromSeconds(10);
this.recognizer.ContinuousRecognitionSession.AutoStopSilenceTimeout =
TimeSpan.FromSeconds(10);
this.recognizer.ContinuousRecognitionSession.ResultGenerated += OnResultGenerated;
this.recognizer.ContinuousRecognitionSession.Completed += OnCompleted;
this.recognizer.Constraints.Add(
new SpeechRecognitionTopicConstraint(
SpeechRecognitionScenario.FormFilling, "Number"));
await this.recognizer.CompileConstraintsAsync();
}
}
async void OnResultGenerated(SpeechContinuousRecognitionSession sender,
SpeechContinuousRecognitionResultGeneratedEventArgs args)
{
Debug.WriteLine(args.Result.Text);
if ((args.Result.Status == SpeechRecognitionResultStatus.Success) &&
(args.Result.Confidence == SpeechRecognitionConfidence.High))
{
int? lotteryNumber = this.lotteryOptions.Parse(args.Result.Text);
if (lotteryNumber != null)
{
this.resultsList.Add((int)lotteryNumber);
if (this.resultsList.Count == this.lotteryOptions.Count)
{
await this.recognizer.ContinuousRecognitionSession.StopAsync();
}
}
}
}
void OnCompleted(SpeechContinuousRecognitionSession sender,
SpeechContinuousRecognitionCompletedEventArgs args)
{
this.taskCompletion.SetResult(
(args.Status == SpeechRecognitionResultStatus.Success) &&
(this.resultsList.Count == this.lotteryOptions.Count));
}
LotteryOptions lotteryOptions;
List<int> resultsList;
TaskCompletionSource<bool> taskCompletion;
SpeechRecognizer recognizer;
}
[/code]
And this might be used by a piece of code like the following:
[code language=”csharp”]
LotteryNumberRecognizer recognizer = new LotteryNumberRecognizer();
try
{
IReadOnlyList<int> numbers = await recognizer.GetNumbersFromUserAsync();
}
catch (TimeoutException)
{
// TBD.
}
[/code]
We could then marry with this some UI in order to present it to the user.
Wrapping up
We’ve introduced the idea of the SpeechRecognizer and some of its capabilities for gathering speech from the user. In the next article, we’ll look at how we can further guide the recognition process and we’ll also look at how we can have the device talk back to the user. In the meantime, don’t forget the links below:
Written by Mike Taulty (@mtaulty), Developer Evangelist, Microsoft DX (UK)