

The DOM is the foundation of the web platform programming model, and its design and performance impacts the rest of the browser pipeline. However, its history and evolution is far from a simple story.
Over the past three years, we’ve embarked on an in-flight refactoring of the DOM in Microsoft Edge, with our eye on a modernized architecture offering better real-world performance and reduced complexity. In this post, we’ll walk you through the history of the DOM in Internet Explorer and Microsoft Edge, and the impact of our recent work to modernize the DOM Tree, which is already resulting in substantially improved performance in the Windows 10 Creators Update.
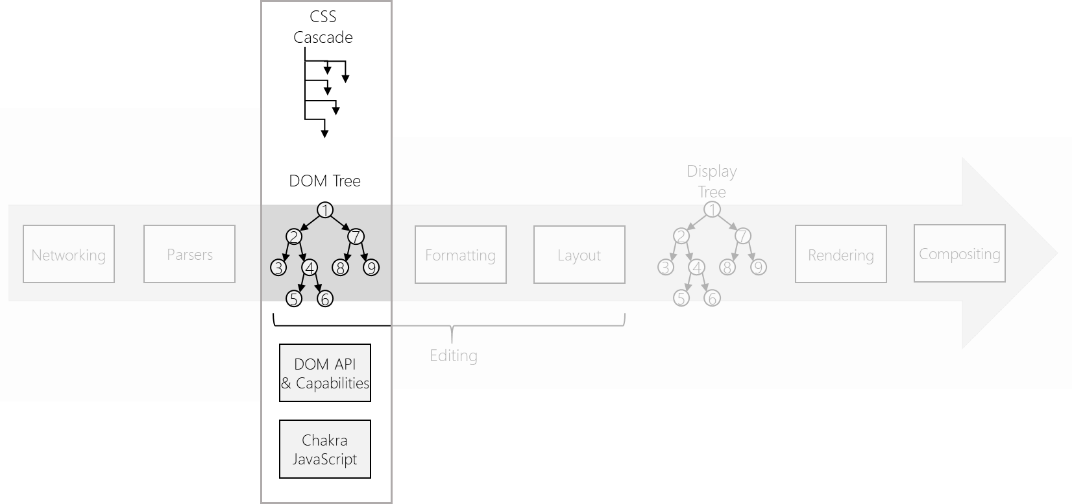
What we think of as “the DOM” is really the cooperation of several subsystems. In Microsoft Edge, this includes JS binding, events, editing, spellchecking, HTML attributes, CSSOM, text, and others, all working together. Of these subsystems, the DOM “tree” is at the center.
Several years ago, we began a long journey to update to a modern DOM “tree” (node connectivity structures). By modernizing the core tree, which we completed in Microsoft Edge 14, we landed a new baseline and the scaffolding to deliver on our promise of a fast and reliable DOM. With Windows 10 Creators Update and Microsoft Edge 15, the journey we started is beginning to bear fruit.
We’re just scratching the surface, but want to take this opportunity to geek out a bit, and share some of the internal details of this journey, starting with the DOM’s arcane history and showcasing some of our accomplishments along the way.
The history of the Internet Explorer DOM tree
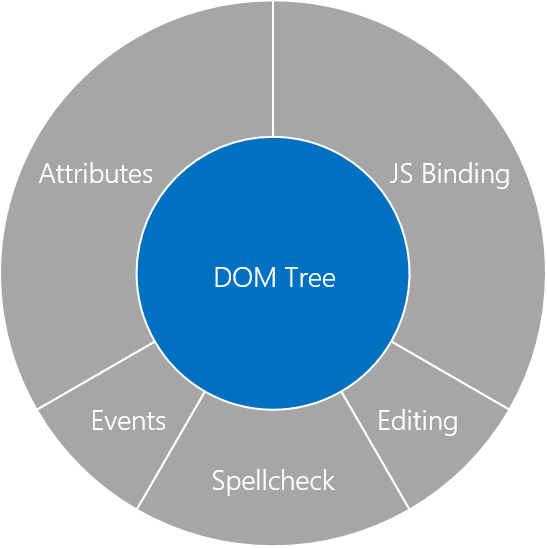
When web developers today think of the DOM, they usually think of a tree that looks something like this:
However nice and simple (and obvious) this seems, the reality of Internet Explorer’s DOM implementation was much more complicated.
Simply put, Internet Explorer’s DOM was designed for the web of the 90s. When the original data structures were designed, the web was primarily a document viewer (with a few animated GIFs and other images thrown in). As such, algorithms and data structures more closely resembled those you might see powering a document viewer like Microsoft Word. Recall in the early days of the web that there was no JavaScript to allow scripting a web page, so the DOM tree as we know it didn’t exist. Text was king, and the DOM’s internals were designed around fast, efficient text storage and manipulation. Content editing (WYSIWYG) was already a feature at the time, and the manipulation paradigm centered around the editing cursor for character insertion and limited formatting.
A text-centric design
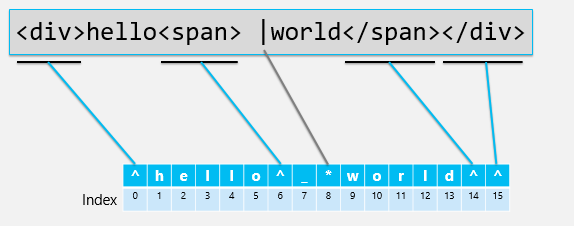
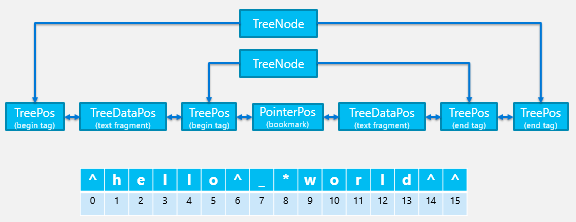
As a result of its text-centric design, the principle structure of the DOM was the text backing store, a complex system of text arrays that could be efficiently split and joined with minimal or no memory allocations. The backing store represented both text and tags as a linear progression, addressable by a global index or Character Position (CP). Inserting text at a given CP was highly efficient and copy/pasting a range of text was centrally handled by an efficient “splice” operation. The figure below visually illustrates how a simple markup containing “hello world” was loaded into the text backing store, and how CPs were assigned for each character and tag.
To store non-textual data (e.g. formatting and grouping information), another set of objects was separately maintained from the backing store: a doubly-linked list of tree positions (TreePos objects). TreePos objects were the semantic equivalent of tags in HTML source markup – each logical element was represented by a begin and end TreePos. This linear structure made it very fast to traverse the entire DOM “tree” in depth-first pre-order traversal (as required for nearly every DOM search API and CSS/Layout algorithm). Later, we extended the TreePos object to include two other kinds of “positions”: TreeDataPos (for indicating a placeholder for text) and PointerPos (for indicating things like the caret, range boundary points, and eventually for “new” features like generated content nodes).
Each TreePos object also included a CP object, which acted as the tag’s global ordinal index (useful for things like the legacy document.all API). CPs were used to get from a TreePos into the text backing store, easily compare node order, or even find the length of text by subtracting CP indices.
To tie it all together, a TreeNode bound pairs of tree positions together and established the “tree” hierarchy expected by the JavaScript DOM as illustrated below.
Adding layers of complexity
The foundation of CPs caused much of the complexity of the old DOM. For the whole system to work properly, CPs had to be up-to-date. Thus, CPs were updated after every DOM manipulation (e.g. entering text, copy/paste, DOM API manipulations, even clicking on the page—which set an insertion point in the DOM). Initially, DOM manipulations were driven primarily by the HTML parser, or by user actions, and the CPs-always-up-to-date model was perfectly rational. But with rise of JavaScript and DHTML, these operations became much more common and frequent.
To compensate, new structures were added to make these updates efficient, and the splay tree was born, adding an overlapping series of tree connections onto TreePos objects. The added complexity helped with performance—at first; global CP updates could be achieved with O(log n) speed. Yet, a splay tree is really only optimized for repeated local searches (e.g., for changes centered around one place in the DOM tree), and did not prove to be a consistent benefit for JavaScript and its more random-access patterns.
Another design phenomenon was that the previously-mentioned “splice” operations that handled copy/paste, were extended to handle all tree mutations. The core “splice engine” worked in three steps, as illustrated in the figure below.
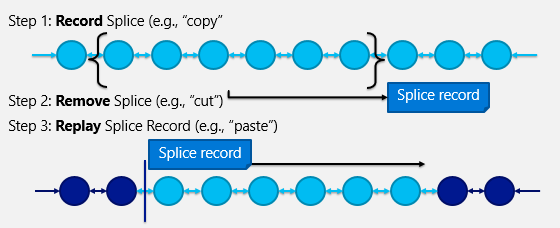
In step 1, the engine would “record” the splice by traversing the tree positions from the start of the operation to the end. A splice record was then created containing command instructions for this action (a structure re-used in the browser’s Undo stack). In step 2, all nodes (i.e., TreeNode and TreePos objects) associated with the operation were deleted from the tree. Note that in the IE DOM tree, TreeNode/TreePos objects were distinct from the script-referenced Element objects to facilitate overlapping tags, so deleting them was not a functional problem. Finally, in step 3, the splice record was used to “replay” (re-create) new objects in the target location. For example, to accomplish an appendChild DOM operation, the splice engine created a range around the node (from the TreeNode‘s begin TreePos to its end), “spliced” the range out of the old location, and created new nodes to represent the node and its children in the new location. As you can imagine, this created a lot of memory allocation churn, in addition to the inefficiencies of the algorithm.
No encapsulation
These are just a few of the examples of the complexity of the Internet Explorer DOM. To add insult to injury, the old DOM had no encapsulation, so code from the Parser all the way to the Display systems had CP/TreePos dependencies, which required many dev-years to detangle.
With complexity comes errors, and the DOM code base was a reliability liability. According to an internal investigation, from IE7 to IE11, approximately 28% of all IE reliability bugs originated from code in core DOM components. This complexity also manifested as a tax on agility, as each new HTML5 feature became more expensive to implement as it became harder to retrofit concepts into the existing architecture.
Modernizing the DOM tree in Microsoft Edge
The launch of Project Spartan created the perfect opportunity modernize our DOM. Free from platform vestiges like docmodes and conditional comments, we began a massive refactoring effort. Our first, and most critical target: the DOM’s core tree.
We knew the old text-centric model was no longer relevant; we needed a DOM tree that actually was a tree internally in order to match the expectations of the modern DOM API. We needed to dismantle the layers of complexity that made it nearly impossible to performance-tune the tree and the other surrounding systems. And finally, we had a strong desire to encapsulate the new tree to avoid creating cross-component dependencies on core data structures. All of this effort would lead to a DOM tree with the right model in place, primed and ready for additional improvements to come.
To make the transition to the modern DOM as smooth as possible (and to avoid building a new DOM tree in isolation and attempting to drop and stabilize untested code at the end of the project—a.k.a. the very definition of “big bang integration”), we transitioned the existing codebase in-place in three phases. The first phase of the project defined our tree component boundary with corresponding APIs and contracts. We chose to design the APIs as a set of “reader” and “writer” functions that operated on nodes. Instead of APIs that look like this:
[code]parent.appendChild(child);
element.nextSibling;[/code]
our APIs looked like this:
[code]TreeWriter::AppendChild(parent, child);
TreeReader::GetNextSibling(element);[/code]
This API design discourages callers from thinking about tree objects as actors with their own state. As a result, a tree object is only an identity in the API, allowing for more robust contracts and hiding representational details, which proved useful in phase 3.
The second phase migrated all code that depended on legacy tree internals to use the newly established component boundary APIs instead. During this migration, the implementation of the tree API would continue to be powered by the legacy structures. This work took the most time and was the least glamorous; it took several dev-years to detangle consumers of the old tree structures and properly encapsulate the tree. Staging the project this way let us release EdgeHTML 12 and 13 with our fully-tested incremental changes, without disrupting the shipping schedule.
In the third and final phase, with all external code using the new tree component boundary APIs, we began to refactor and replace the core data structures. We consolidated objects (e.g., the separate TreePos, TreeNode, and Element objects), removed the splay tree and splice engine, dropped the concept of PointerPos objects, and removed the text backing storage (to name a few). Finally, we could rid the code of CPs.
The new tree structure is simple and straightforward; it uses four pointers instead of the usual five to maintain connectivity: parent, first-child, next, and previous sibling (last-child is computed as the parent’s first-child’s previous sibling) and we could hide this last-child optimization behind our TreeReader APIs without changing a single caller. Re-arranging the tree is fast and efficient, and we even saw some improvements in CPU performance on public DOM APIs, which were nice side-effects of the refactoring work.
With the new DOM tree, reliability also improved significantly, dropping from 28% of all reliability issues to just around 10%, and at the same time providing secondary benefits of reducing time spent debugging and improving team agility.
The next steps in the journey
While this feels like the end of our journey, in fact it’s just the beginning. With our DOM tree APIs in place and powered by a simple tree, we turned our attention to the other subsystems that comprise the DOM, with an eye towards two classes of inefficiencies: inefficient implementations inside the subsystems, and inefficient communication between them.
For example, one of our top slow DOM APIs (even after the DOM tree work) has historically been querySelectorAll. This is a general-purpose search API, and uses the selectors engine to search the DOM for specific elements. Not surprisingly, many searches involve particular element attributes as search criteria (e.g., an element’s id, or one of its class identifiers). As soon as the search code entered the attributes subsystem, it ran into a whole new class of inefficiencies, completely unrelated to those addressed by the new DOM tree.
For the attributes subsystem, we are simplifying the storage mechanism for element content attributes. In the early days of the web, DOM attributes were primarily directives to the browser about how to display a piece of markup. A great example of this is the colspan attribute:
[code language=”html”]
<tr>
<td colspan=”2″>Total:</td>
<td>$12.34</td>
</tr>
[/code]
colspan has semantic meaning to the browser and thus has to be parsed. Given that pages weren’t very dynamic back then and attributes were generally treated like enums, IE created an attribute system that was optimized around eager parsing for use in formatting and layout.
Today’s app patterns, however, heavily use attributes like id, class, and data-*, which are treated less like browser directives and more like generic storage:
[code language=”html”]
<li id=”cart” data-customerid=”a8d3f916577aeec” data-market=”en-us”>
<b>Total:</b>
<span class=”total”>$12.34</span>
</li>
[/code]
Thus, we’re deferring most work beyond the bare minimum necessary to store the string. Additionally, since UI frameworks often encourage repeated CSS classes across elements, we plan to atomize strings to reduce memory usage and improve performance in APIs like querySelector.
Though we still have plenty of work planned, with Windows 10 Creators Update, we’re happy to share that we’ve made significant progress!
Show me the money
Reliably measuring and improving performance is hard and the pitfalls of benchmarking are well documented. To get the most holistic view of browser performance possible, the Microsoft Edge team uses a combination of user telemetry, controlled measurement real-world scenarios, and synthetic benchmarks to guide our optimizations.
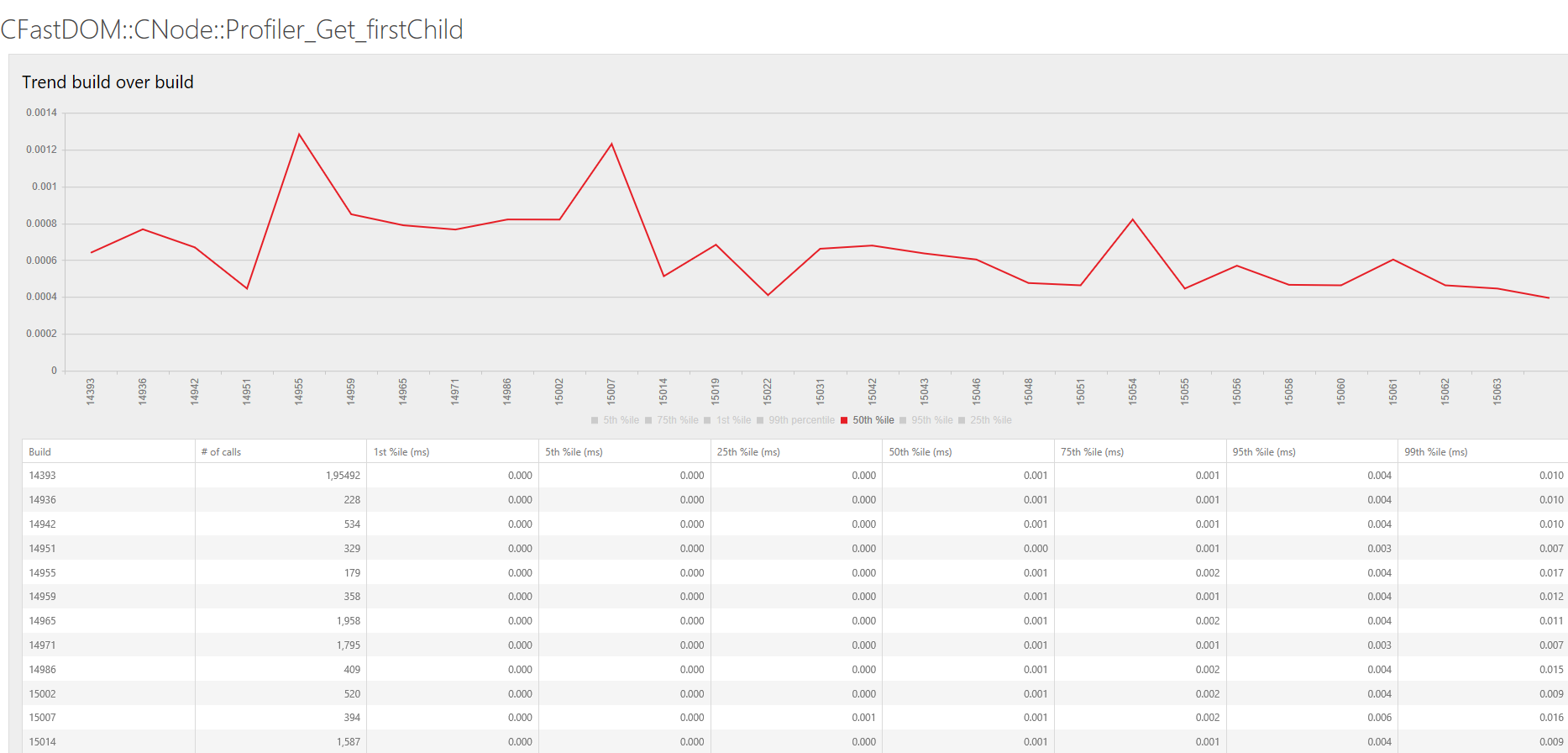
User telemetry “paints with a broad brush”, but by definition measures the most impactful work. Below is an example of our build-over-build tracking of the firstChild API across our user base. This data isn’t directly actionable, since it doesn’t provide all the details of the API call (i.e. what shape and size is the DOM tree) needed for performance tuning, but it’s the only direct measurement of the user’s experience and can provide feedback for planning and retrospectives.
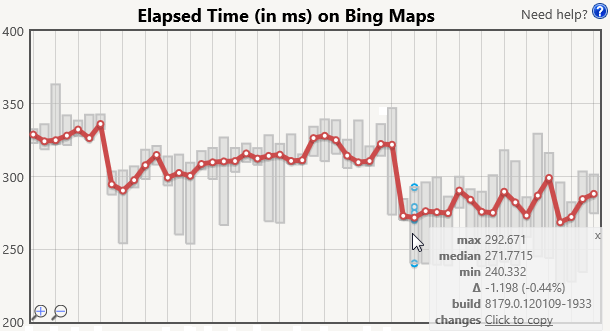
We highlighted our Performance lab and the nitty-gritty details of measuring browser performance a while ago, and while the tests themselves and the hardware in the lab has changed since then, the methodology is still relevant. By capturing and replaying real-world user scenarios in complex sites and apps like Bing Maps and Office 365, we’re less likely to overinvest in narrowly applicable optimizations that don’t benefit users. This graph is an example of our reports for a simulated user on Bing Maps. Each data point is a build of the browser, and hovering provides details about the statistical distribution of measurements and links to more information for investigating changes.
Our Performance lab’s fundamental responsibility is to provide the repeatability necessary to test and evaluate code changes and implementation options. That repeatability also serves as the platform for synthetic benchmarks.
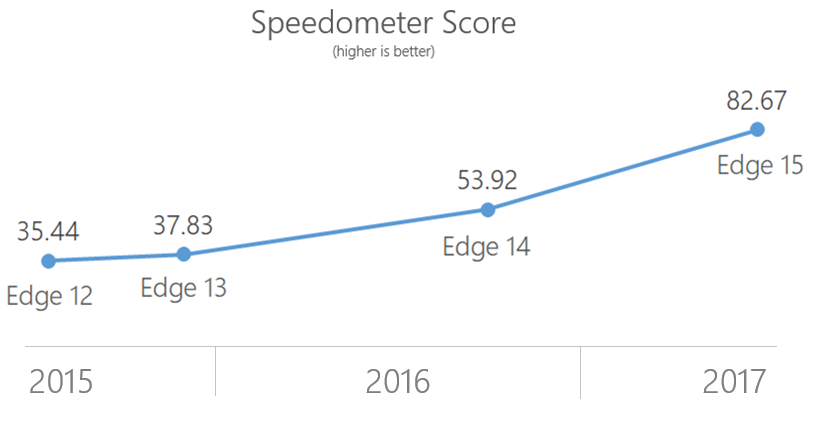
In the benchmark category, our most exciting improvement is in Speedometer. Speedometer simulates using the TodoMVC app for several popular web frameworks including Ember, Backbone, jQuery, Angular, and React. With the new DOM tree in place and other improvements across other browser subsystems like the Chakra JavaScript engine, the time to run the Speedometer benchmark decreased by 30%; in the Creators update, our performance focus netted another improvement of 35% (note that Speedometer’s scores are a measure of speed and thus an inverse function of time).
Of course the most important performance metric is the user’s perception, so while totally unscientific, we’ve been super excited to see others notice our work!
2 more big things I've noticed: 1) faster DOM manipulation and…
— Bryan Crow (@BryanTheCrow) March 22, 2017
kudos to Microsoft, latest Edge version is nearly 50% faster on https://t.co/KFX8Y4SpDI (and now crushes Firefox)
— Jeff Atwood (@codinghorror) March 31, 2017
Latest Edge also 2x faster for Ember. Finally, some change I can believe in! Good work Edge team. 👏 pic.twitter.com/nj6Qld4aTW
— Jeff Atwood (@codinghorror) March 31, 2017
We’re not done yet, and we know that Microsoft Edge is not yet the fastest on the Speedometer benchmark. Our score will continue to improve as a side effect of our performance work and we’ll keep the dev community updated on our progress.
Conclusion
A fast DOM is critical for today’s web apps and experiences. Windows 10 Creators Update is the first of a series of releases focused on performance on top of a re-architected DOM tree. At the same time, we’ll continue to improve our performance telemetry and community resources like the CSS usage and API catalog.
We’re just beginning to scratch the surface of what’s possible with our new DOM tree, and there’s still a long journey ahead, but we’re excited to see where it leads and to share it with you! Thanks!
― Travis Leithead & Matt Kotsenas, Program Managers, Microsoft Edge