

Building in 10k: Markup for Accessibility, Clarity, and Affordance
In the previous post in this series, I talked a lot about how the 10k Apart contest site began to materialize in terms of structure and content. Once the planning was done, I was finally able to start building the site in earnest.
Where do I begin?
Generally, the first step I take in building any site is to drop some sample content into a fresh HTML document and then work my way through it, marking things up as I go. In the case of this project, I decided that sample content would be all of the patterns I had identified in the wireframes. It seemed like a solid starting point that would get me pretty far in terms of building out the bits I’d need to flesh out the full site.
First things first, I copied in the content from the wireframes. Then I began asking one simple question over and over: How can I use markup make this better?
The purpose of markup is to twofold:
- To give structure to a document; and
- To convey (and enhance) the meaning of the document’s content.
With that question in mind, I began to work my way, bit by bit, through the document, always on the lookout for opportunities to make it a little more meaningful, a little more usable. I was, of course, ever-mindful of that looming 10kB limit too. Markup tends to be pretty small, but I wanted to minimize cruft and focus on markup that actually added value to the document.
What’s the minimum viable structure?
Every page needs structure, so I started there. First off, I dropped in a minimal HTML5 shell:
| <!DOCTYPE html> | |
| <html id="akapart" lang="en"> | |
| <head> | |
| <meta charset="utf-8"> | |
| <title>10k Apart</title> | |
| </head> | |
| <body> | |
| … My content went here … | |
| </body> | |
| </html> |
Have I told you how thankful I am for that simplified DOCTYPE? It’s worth noting that I added an id to html element to act as a site identifier. This is a practice I picked up years ago from Eric Meyer as a helpful option for folks who rely on user styles and want to override a specific site’s styles rather than every site’s.
With the minimal shell in place, I set to work marking up the content in my patterns document. I began by surveying the content and identifying key regions like the site banner, navigation, primary content, and footer. All of these pieces have semantic meaning and they also have associated HTML elements. Let’s step through them, one by one.
A “banner” is introductory content for a web page. ARIA granted us the ability to identify a site’s banner using role=”banner”, so it would be completely reasonable (and accessible) to mark up the site’s banner like this:
Incidentally, HTML5 introduced the header element, which operated in a similar way. Semantically, it’s intended for introductory content. The header element can be used directly in the document body as well as within sectioning elements (like article and section). What’s really cool is that the first header encountered in the body (but not inside a sectioning element) is exposed to assistive technology as the site’s banner. That means we can skip adding the role and just do this:
| <header> | |
| … Banner content goes here … | |
| </header> |
Why do we care about the semantic equivalence? Well, assistive technologies can use landmark roles like “banner” to enable a user to move around more quickly in a document.
The next thing I needed to address in the document was the navigation. There’s an ARIA role for that: role=”navigation”. However, there’s also a corresponding HTML5 tag: nav, which is a bit less verbose. Done and done. Well, almost. In order to identify the purpose of the navigation, I can enlist another ARIA property: aria-label:
This ensures assistive technology exposes the purpose of the navigation to users. Edge with Narrator, for example will read out “Main Navigation, navigation, navigation landmark”.
NVDA with Firefox would read this out as “Main Navigation, navigation landmark.”
Next up is the primary content. ARIA denotes that with role="main", but the newer main element accomplishes the same thing more succinctly.
| <main> | |
| … Primary content goes here … | |
| </main> |
Finally there’s the footer. HTML5 has the footer element which, like header, can operate in either a sectioning context or a page context. And like header, the first footer encountered in the body (again, provided it’s not a descendent of a sectioning element) will automatically be granted a semantic value equivalent to ARIA’s “contentinfo” role. That role denotes meta information about the content, like copyright. Just what we need!
Rolled all together, the document structure was simple and semantic, with nary a div in sight:
| <header> | |
| … Banner content goes here … | |
| <nav aria-label="Main Navigation"> | |
| … Navigation goes here … | |
| </nav> | |
| </header> | |
| <main> | |
| … Primary content goes here … | |
| </main> | |
| <footer> | |
| … Copyright, etc. goes here … | |
| </footer> |
Where can I provide more meaning?
With the basic document structure in place, I began to look at the individual patterns with an eye for where I could add value using markup. In many cases, simple tried and true elements like headings, paragraphs, and lists made the most sense. For example, the navigation is really a list of links. The order really doesn’t matter, so I used a ul:
The cool thing about that approach is that when assistive technology encounters that navigation landmark, users get an even more useful information. So, going back to the NVDA example from earlier, this would be read as “Main Navigation, navigation landmark. List with three items.” That’s super helpful!
HTML’s native semantics can do a ton to super-charge our documents like this. Remember folks, not everything should be a div.
What needs to be identified?
The “common wisdom” within the web design world is to avoid using the id attribute. The oft-cited reason for this is that in a CSS selector, an id selector (e.g., #foo) carries a lot of weight in specificity calculation and often lead designers to create unnecessarily over-specific selectors. That is 100% true, but I think it gives id a bad rap. Modern attitudes toward id often remind me of the antagonism many of us felt for table when we were trying to get folks to move from table-based layouts to CSS. It took the best of us down some pretty weird rabbit holes. The table element is absolutely the best choice for marking up tabular content.
The id attribute is used to identify a specific element on the page. You can use it for CSS, sure, but it has other uses as well:
- It creates an anchor to that element in the document (try it out by adding “#comments” to the address bar of your browser);
- It creates a simple and inexpensive means of document traversal in JavaScript:
document.getElementById(); - It creates a reference-able identifier useful for associating the identified element with another one via
for,aria-labelledby,aria-describedby, and other attributes.
As with many things, id can certainly be overused, but that doesn’t mean you shouldn’t use it. In terms of the 10k Apart site, I opted to use it in the forms (which I will discuss shortly) and extensively on the FAQ page and the Official Rules page.
On both of those pages, I used id to create anchor points so I could point folks directly to certain sections. On the FAQ page, which is relatively long, I used short id values like “size”, “js” and “a11y” (short for “accessibility”). The Official Rules are a bit longer, so in order to save some bits, I opted to use the section character (“§”) as a prefix to the id values. If you look at the source of that page, you’ll see id values like “§–1”, “§–2”, and “§–3”. They may look weird, but they are valid id values.
What are the common patterns?
The id attribute is great for identifying specific elements, but there are lots of instances where elements share a function. One example of that is the gallery of projects and the gallery of judges. And so I chose to classify the two lists as being of an ilk, using a class of, you guessed it, “gallery”.
Another example of elements that are related are the various project instances. Each instance is a “project”, but a project has certain characteristics when it is part of a gallery and other characteristics when it’s on its own page. Each instance shares the class of “project” but can also receives a modifier class to denote its context. I chose to follow the BEM syntax for classifying elements, but there numerous other ways to accomplish the same goal. Here’s what I came up with:
.project— Used for all projects;.project--page— Used for the project on its own page;.project--hero— Used for the Grand Prize winner in the final version of the homepage;.project--winner— Used for projects that have won a prize; and.project--preview— Used for the JavaScript-based live preview accompanying the entry form.
Since I’m on the subject, I also used the BEM approach to keep my styles modular. Continuing with the project example, a project instance could have multiple properties associated with it:
.project__author— The person who submitted the project;.project__name— The name they gave the project; and.project__won— The prize a project won
Doing this allowed me to isolate project-related styles to specific elements based solely on their purpose, rather than the markup they happened to use (which might change from instance to instance, depending on the needs of the page).
How can I make the forms better?
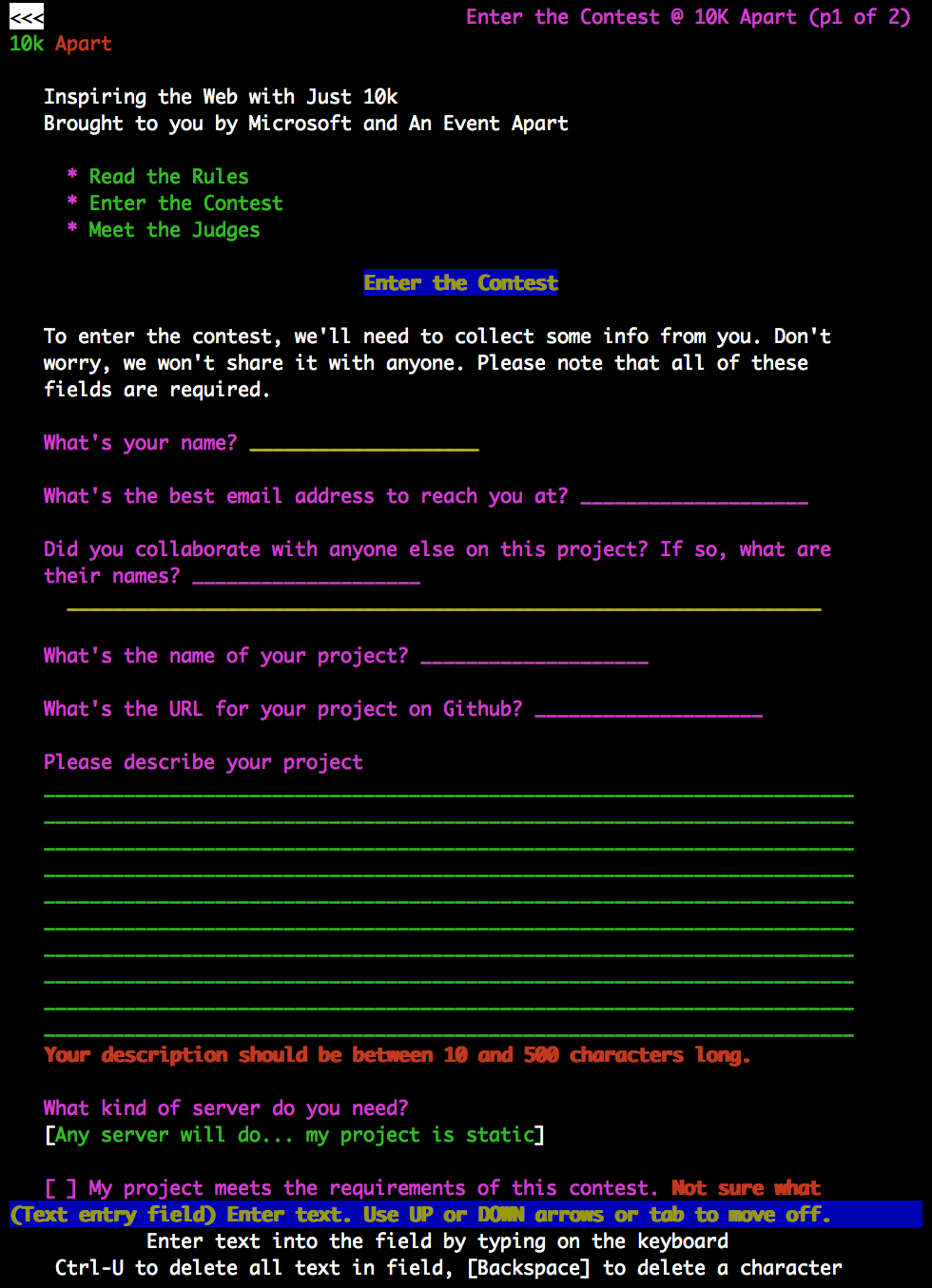
Content, the official rules, and the projects themselves are all obviously quite important to this site, but without a usable entry form, the whole project is kinda pointless. Part of making more usable forms for the site started with the planning and began with eliminating unnecessary fields. That removed a lot of the noise from the entry form. The next step was humanizing the language, which I mentioned in the last post. Practically, it meant moving away from terse and rather useless labels like “Name” toward more conversational labels that actually beg a response, like “What’s your name?”.
With solid, conversational labels in place, I then went about associating them with the various form controls. To start with, I marked all of the standard fields up as input elements with no type assignment (meaning they all defaulted to “text”). I then marked up each bit of label text in a label element and then tied the two together using a for attribute on the label that referenced the id attribute of the associated field. I did the same with the select, textarea, and checkbox controls. Here’s an example:
| <label for="n">What’s your name?</label> | |
| <input id="n" name="n"> |
I opted to use single character id values to save room so I could spend additional markup characters on additional enhancements.
Next, I went through the form and looked for fields that were asking for specific kinds of structured information, like an email address or a URL. When that was the case, I used the corresponding input type. Here’s an early instance of the email field, for example:
| <label for="e">What’s the best email address to reach you at?</label> | |
| <input type="email" id="e" name="e"> |
My next pass added attributes to signify if a field was required. To get the greatest amount of coverage in this area, I doubled up the required attribute with aria-required="true". It’s redundant, but not all assistive tech/browser combinations treat them as equivalent… yet.
| <label for="n">What’s your name?</label> | |
| <input id="n" name="n" | |
| required aria-required="true" | |
| > |
I used the next pass to control how content could be entered into the fields in order to provide a better experience for folks in browsers that support autocorrection, automatic capitalization, and the like. (If you’re interested, there’s a great overview of best practices for streamlining data entry, especially on mobile.) For the “name” field, that meant turning off autocorrect and setting it to autocapitalize words.
| <label for="n">What’s your name?</label> | |
| <input id="n" name="n" | |
| required aria-required="true" | |
| autocorrect="off" autocapitalize="words" | |
| > |
Then I went through and provided some silly placeholders to suggest the kind of content a user should be entering into the field.
| <label for="n">What’s your name?</label> | |
| <input id="n" name="n" | |
| required aria-required="true" | |
| autocorrect="off" autocapitalize="words" | |
| placeholder="Sir Tim Berners Lee" | |
| > |
And my final pass added support for auto-complete, which enables users of supporting browsers to fill out the form even more quickly by identifying the specific information the browser should supply for each field.
| <label for="n">What’s your name?</label> | |
| <input id="n" name="n" | |
| required aria-required="true" | |
| autocorrect="off" autocapitalize="words" | |
| placeholder="Sir Tim Berners Lee" | |
| autocomplete="name" | |
| > |
If you’re intrigued by this idea and want to know more, you should definitely read Jason Grisby’s treatise on autocomplete.
It may not seem like much in the grand scheme of things, but those minor markup tweaks add so much to the experience. And if a particular browser or browser/assistive tech combo doesn’t support a feature, no big deal. An input can be as simple as a text input and it’s ok. We’re still doing server-side validation, so it’s not like users who can’t take advantage of these enhancements will be left out in the cold.
And speaking of server-side validation, I should probably spend a few minutes talking about how that factors into the markup.
What if the form has an error?
Let’s say you forget to enter your name for some reason and your browser doesn’t pay attention to the HTML5 field types and attributes. The server will catch the error and return you to the form with all of the info you entered intact. It also summarizes the errors and provides some useful messaging about the error and how to fix it or why it’s important.
First off, a summary of errors will appear at the top of the form:
| <div class="errors" role="alert" tabindex="0"> | |
| <p>Hmm, there seems to be an error with your submission.</p> | |
| <ol> | |
| <li>We need <a href="#n">your name</a></li> | |
| </ol> | |
| </div> |
Here we have an introductory message followed by a list of errors. Each error contains a link that anchors you directly to the corresponding field. (Yay id!) The whole message also has an ARIA role of “alert” indicating users of assistive tech should be informed of this content immediately after the page loads. A tabindex of 0 is also added to ensure it receives focus so the contents are read.
Drilling down to the field itself, we have the label, the field, and the error message. The label and the field are already associated (via the for–id connection I covered earlier), but I needed to associate the error now too. In order to do that, I used aria-describedby which also makes use of id.
| <label for="n">What’s your name?</label> | |
| <input id="n" name="n" | |
| required aria-required="true" | |
| autocorrect="off" autocapitalize="words" | |
| placeholder="Sir Tim Berners Lee" | |
| autocomplete="name" | |
| value="" | |
| aria-invalid="true" | |
| aria-describedby="e-n" | |
| > | |
| <strong id="e-n">You want to get credit for your project right? Please provide your name.</strong> |
In this case aria-describedby points to a single element (strong#e-n), but the attribute can actually reference multiple id values, separated by spaces. It’s worth noting I’ve also marked the field as invalid for assistive tech using aria-invalid="true".
Again, a teensy-tiny tweak to the markup that pays huge dividends in terms of usability.
Oh yeah, and one last thing: the form works perfectly in Lynx.
What did we learn?
I covered a ton of stuff in this piece, so here’s a little summary of takeaways if you’re a fan of that sort of thing:
- Markup for structure and semantics — Choose your HTML elements with purpose;
- Labeling elements reduces ambiguity —
aria-labelcan (and should) be your friend; - Don’t shy away from
id— You don’t have to use it in your CSS,idhas a bunch of other uses; - Classify similar elements — that’s what the
classattribute is for, the naming approach is up to you; - Associate form labels with controls — no excuses… just do it;
- Use the right field type — HTML5 offers a bunch of options, get familiar with them;
- Indicate required fields — do it in your content and in your form controls;
- Manage autocorrection and capitalization — your virtual keyboard users will thank you;
- Suggest possible responses — but keep in mind the
placeholderattribute is a suggestion, not a label; - Facilitate auto-completion — again, your users will thank you; and
- Handle errors well — make it easy for users to find and correct errors.
Where to next?
With a solid set of markup patterns in place, I built out the site in earnest, following along with the wireframes. Once that was done, the next step was to design the thing. Well, technically some of the design had already begun while I was working on markup, but you know what I mean. Designer Stephanie Stimac will be joining me to talk about that process in the next post. Stay tuned!
― Aaron Gustafson, Web Standards Advocate