
言語モデル「Mu」とそれによって誕生した Windows の設定エージェントをご紹介

※本ブログは、米国時間 6 月 23 日に公開された “Introducing Mu language model and how it enabled the agent in Windows Settings” の抄訳を基に掲載しています。
本日は、最新のオンデバイス小規模言語モデル「Mu」をご紹介します。Mu は複雑な入力と出力の関係性の推論を必要とするシナリオに適した言語モデルであり、ローカル実行時に効率的に動作し、高いパフォーマンスを発揮するよう設計されています。特に、自然言語の入力クエリを設定機能の呼び出しにマッピングするといった、Windows の設定エージェントの駆動の強化に使用されます。現在は、Copilot+ PC の Dev チャネルの Windows Insider の皆様 (英語) にご利用いただけます。
Mu はニューラル プロセッシング ユニット (NPU) に完全に処理を任せ、1 秒あたり 100 トークン以上の応答速度を実現します。これは、設定シナリオのエージェントに求められる厳しい UX 要件を満たす速度です。この記事では、Mu の設計およびトレーニングの詳細と、Windows の設定にエージェントを組み込むうえでどのような調整を行ったのかについて説明します。
Mu のモデル トレーニング
Phi Silica (英語) を NPU 上で実行できるようにした際に、私たちは最適な性能と効率を得るためにどのようにモデルをチューニングすればよいかについて貴重な知見を得ることができました。その知見を活かして NPU とエッジ デバイス上で効率的に動作するようゼロから設計・開発したのが、この極小規模のタスク特化型言語モデル Mu です。
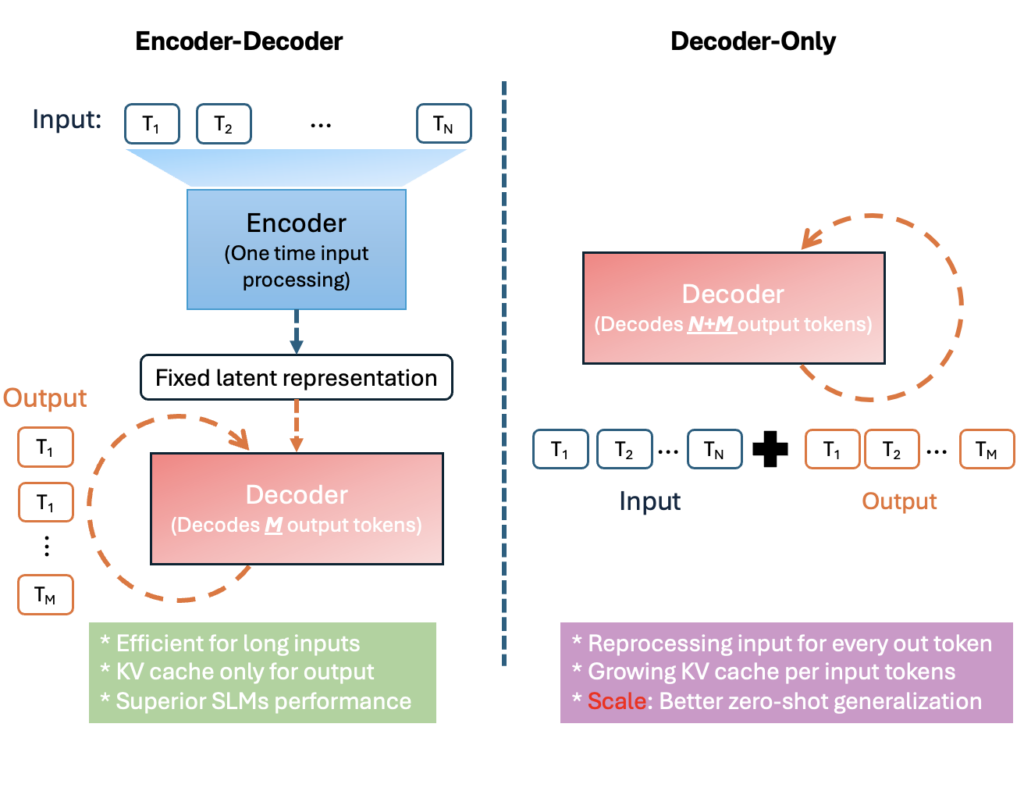
エンコーダー・デコーダー アーキテクチャとデコーダーのみのアーキテクチャの比較
Mu は小規模な環境、特に Copilot+ PC の NPU 向けに最適化された、3 億 3,000 万パラメーターの効率的なエンコーダー・デコーダー型言語モデルです。トランスフォーマーのエンコーダー・デコーダー型アーキテクチャを採用しており、「エンコーダー」が入力を固定長の潜在表現に変換した後、その表現に基づいて「デコーダー」が出力トークンを生成します。
この設計により、効率性が大幅に向上します。上図のとおり、エンコーダー・デコーダー型アーキテクチャでは入力の潜在表現を再利用するのに対し、デコーダーのみのアーキテクチャでは入力と出力の完全なシーケンスを考慮する必要があります。入力トークンと出力トークンを分離することで、Mu のワンタイム エンコーディングでは計算量とメモリ消費が大幅に削減されます。実際の動作では、専用ハードウェアにおけるレイテンシが短縮され、処理能力が高まります。たとえば、Qualcomm Hexagon NPU (モバイル AI アクセラレータ) 上では、Mu のエンコーダー・デコーダー アプローチは同規模のデコーダーのみのモデルと比較して、最初の応答までのレイテンシを約 47% 短縮し、デコーディング速度を 4.7 倍向上させました。これは、デバイス上でリアルタイムに動作するアプリケーションにおいてはきわめて重要なメリットです。
Mu の設計は、NPU の制約と能力に合わせて慎重に行われました。具体的には、ハードウェアの並列処理能力とメモリ制限に合うようにモデル アーキテクチャとパラメーター形状を調整しました。レイヤーの次元 (隠れ層のサイズやフィードフォワード ネットワークの幅など) は、NPU が推奨するテンソル サイズとベクトル化単位に合致するよう選択し、行列乗算などの演算が最大効率で実行されるようにしました。また、エンコーダーとデコーダー間のパラメーター分布も最適化しました。検証の結果、パラメーターあたりのパフォーマンスを最大化するには、およそ 2 対 1 の配分 (例: ある構成ではエンコーダー層 32 に対してデコーダー層 12) が有効であることがわかりました。
さらに、Mu は特定のコンポーネントで重みを共有して総パラメーター数を削減しています。たとえば、入力トークンの埋め込みと出力トークンの埋め込みを関連付けて、入力トークンの表現と出力ロジットの生成に 1 組の重みを使用します。これにより、メモリを節約できるだけでなく (メモリに制約のある NPU では重要)、エンコーディングの語彙とデコーディングの語彙の一貫性も向上させることができます。
最後に、Mu は組み込み先のランタイムでサポートされている、NPU に最適化された演算子のみで演算を実行します。サポートされていないまたは非効率な演算を避けることで、NPU のアクセラレーション能力を最大限に活用できます。このようなハードウェアを考慮した最適化により、Mu はトータルで高速なオンデバイス推論に非常に適しています。
10 分の 1 のサイズに凝縮された性能
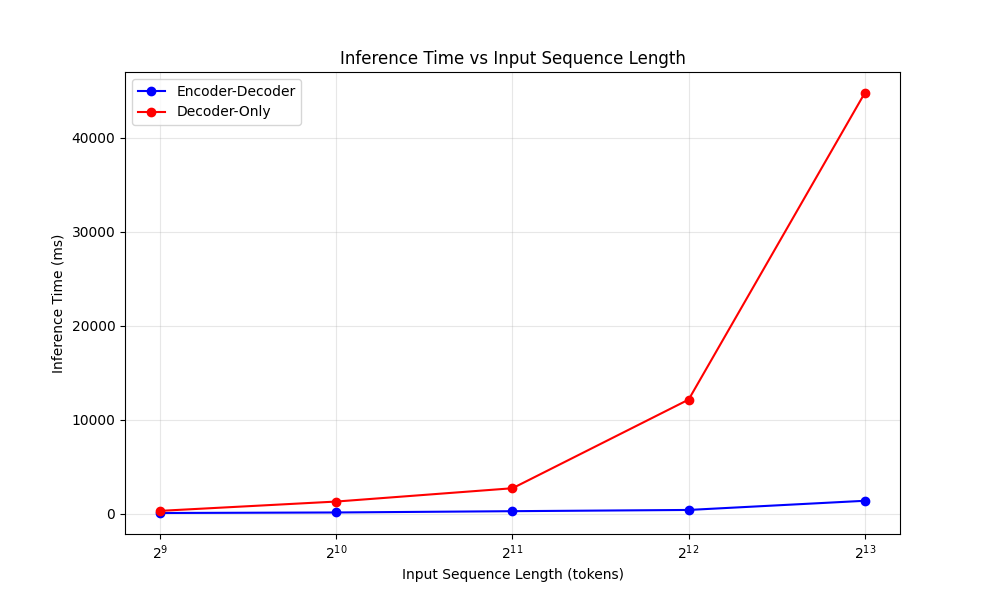
Mu は次の 3 つのトランスフォーマーの改良手法を取り入れることで、小規模モデルながら高いパフォーマンスを発揮しています。
- Dual LayerNorm (前後での LN) – 各サブ レイヤーの前後で正規化を行うことで、活性化を適切なスケールに保ち、最小限のオーバーヘッドでトレーニングを安定させます。
- Rotary Positional Embeddings (RoPE) – 複素数回転により相対位置情報をアテンション計算に組み込むことで、長い文脈の推論処理を改善し、トレーニング時よりも長いシーケンスへのシームレスな外挿を可能にします。
- Grouped-Query Attention (GQA) – ヘッドの各グループでキーと値のセットを共有することで、ヘッドの多様性を維持しながら、アテンション パラメーターの数とメモリ消費を大幅に削減し、NPU 上での高速化と省電力化を実現します。
また、性能をさらに向上させるために、ウォームアップ・安定・減衰スケジュールや Muon Optimizer などのトレーニング手法を採用しました。これらを組み合わせることで、エッジ デバイスの限られたリソース枠内での Mu の精度と推論速度を向上させています。
Mu のトレーニングは、Azure Machine Learning の A100 GPU を活用して、複数のフェーズに分けて実施しました。Phi モデルの開発で初めて採用した手法に従い、まずは言語の構文、文法、意味論、そして世界に関する知識を学習するために、数千億もの教育的価値の高いトークンでの事前学習から始めました。
続いて、精度をさらに高めるために、Microsoft の Phi モデルからの蒸留を行いました。Phi のナレッジを一部取り込むことで、Mu は驚くべきパラメーター効率を実現しています。こうしたプロセスを経て、多様なタスクに対応するベース モデルが完成しました。ここからさらにタスク固有のデータと組み合わせ、Low-Rank Adaptation (LoRA) 手法によるファインチューニングを加えることで、モデルの性能を劇的に向上させることが可能です。
Mu の精度は、SQUAD (英語)、CodeXGlue (英語)、Windows 設定エージェント (後述) などの複数のタスクでファイン チューニングを行い、その結果で評価しました。タスク特化型の Mu はパラメーター数が数億ほどの小規模モデルであるにもかかわらず、多くのタスクで驚異的な性能を発揮しています。
Mu と同様にファインチューニングされた Phi-3.5-mini と比較したところ、Mu はサイズが 10 分の 1 でありながら性能はほぼ同等で、数万の入力コンテキスト長と毎秒 100 を超える出力トークンを処理できることがわかりました。
| タスク/モデル | ファインチューニングされた Mu | ファインチューニングされた Phi |
| SQUAD | 0.692 | 0.846 |
| CodeXGlue | 0.934 | 0.930 |
| 設定エージェント | 0.738 | 0.815 |
モデルの量子化とモデルの最適化
Mu モデルをオンデバイスで効率的に動作させるために、Copilot+ PC 上の NPU に合わせた高度なモデル量子化手法を適用しました。
使ったのは Post-Training Quantization (PTQ) という手法で、モデルの重みと活性化を浮動小数点から整数表現 (主に 8 ビットと 16 ビット) に変換しました。PTQ により、再学習する必要なく完全に学習済みのモデルを量子化でき、展開スケジュールを大幅に短縮しながら、Copilot+ PC 上で効率的に動作するよう最適化することができました。このアプローチによって、モデルの精度を維持しつつ、ユーザー エクスペリエンスに影響させることなく、メモリ消費と計算要件を大幅に削減できました。
量子化は最適化パイプラインの一部にすぎません。AMD、Intel、Qualcomm といった半導体パートナーとも緊密に連携して、Mu 実行時の量子化演算が対象の NPU に対して十分に最適化されるようにしました。たとえば、数学演算子の調整、ハードウェア固有の実行パターンへの適合、さまざまなチップでの性能の検証などを行いました。こうした最適化のプロセスを経て、エッジ デバイスにおけるきわめて効率的な推論を実現しました。Surface Laptop (第 7 世代) での出力生成は毎秒 200 トークンを超えます。
エッジ デバイス上で Wikipedia (https://en.wikipedia.org/wiki/Microsoft) のコンテキストを使用して質問応答タスクを実行する Mu
モデルに大量の入力コンテキストが提供されているにもかかわらず、トークン処理速度が高く、最初の応答までの時間が非常に短い点が注目です。
最先端の量子化手法とハードウェア固有の最適化を組み合わせることで、リソースの制約があるアプリケーションでの実運用においても Mu は優れた効果を発揮します。次のセクションでは、Copilot+ PC の設定に新しい Windows エージェントを組み込むために Mu をどのように調整したかを説明します。
設定エージェントのモデルをチューニング
Windows をさらに使いやすくするために、私たちは数百ものシステム設定の変更に取り組むことにしました。目標は、設定内に AI エージェントを組み込んで自然言語を理解できるようにし、関連する取り消し可能な設定をシームレスに変更できるようにすることでした。また、よりスムーズなユーザー エクスペリエンスを実現するために、このエージェントを既存の検索ボックスに統合することにも取り組みました。それには膨大な数の設定についてレイテンシをきわめて低く抑える必要がありました。さまざまなモデルをテストした結果、Phi LoRA は精度の目標は満たせましたが、サイズが大きすぎてレイテンシの目標には届きませんでした。Mu は適切な特性を備えていましたが、タスクに特化したチューニングを行い、Windows の設定で適切な性能を発揮できるようにする必要がありました。
このシナリオでは、ベースラインの Mu が性能と電力消費の点で優れていましたが、ファインチューニングを行わずに同じデータを使用すると精度が 2 分の 1 に下がりました。この差を埋めるために、トレーニングのスケールを 360 万サンプル (1,300 倍) に拡大し、設定項目を 50 から数百に増やしました。自動ラベリング、メタデータによるプロンプト チューニング、多様な言い回しの調整、ノイズ挿入、スマート サンプリングといった合成アプローチを採用した結果、設定エージェントに使用した Mu のファインチューニングは、品質目標を無事クリアしました。応答時間は 500 ミリ秒を下回り、数百の設定項目に対応する応答性と信頼性に優れた設定エージェントを作成できました。下の画像は、自然言語クエリからマッピングされた設定アクションが UI に表示されているようすです。エクスペリエンスがどのように統合されているかがおわかりいただけると思います。
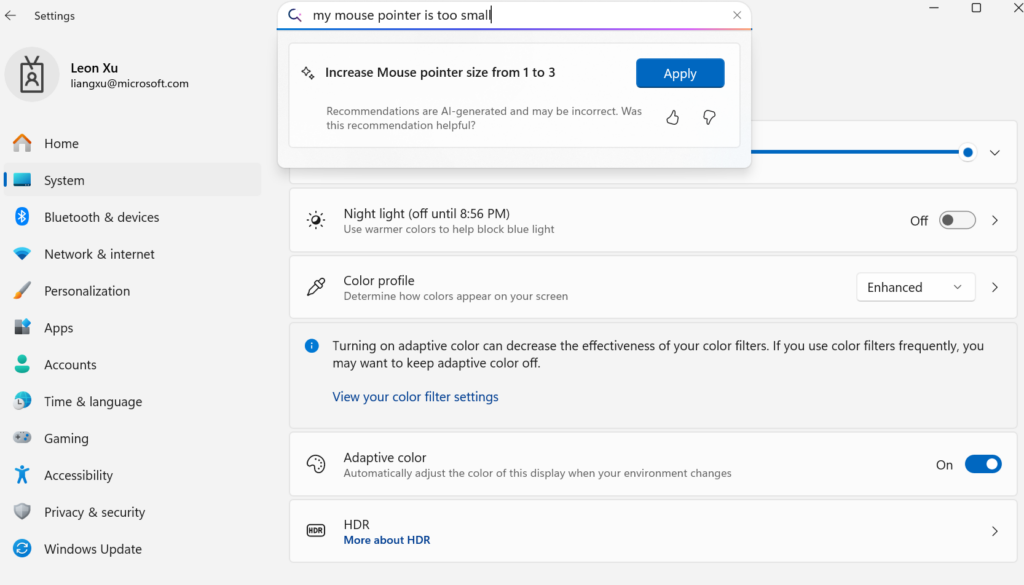
設定エージェントのスクリーンショット
他にも、短くて曖昧なクエリが入力された場合にも対応できるように、実際のユーザー入力や合成クエリ、一般的な設定を組み合わせた多様な評価セットを用意し、モデルが幅広いシナリオをうまく処理できるかも確認しました。その結果、明確に意図がわかる複数単語のクエリでは高いパフォーマンスを発揮した一方、短い入力や単語の一部のみの入力で正確に解釈するためのコンテキストが不十分な場合はパフォーマンスが低下しました。これに対処するため、設定エージェントを設定内の検索ボックスに組み込みました。すると、複数単語のしきい値を満たさない短いクエリでは、引き続きその語彙や意味からの検索結果が検索ボックスに表示され、しきい値を満たした場合は、エージェントが精度の高いアクション可能な応答を返せるようになりました。
Windows の設定項目は膨大であるため、それを管理すること自体が課題でもあります。特に、機能が重複している場合は難しくなります。たとえば、「明るくして」という単純なクエリでも、複数の設定変更を意味していることがあります。ユーザーがモニターを 2 台使用していたら、プライマリとセカンダリのどちらのモニターの輝度を上げたいのかは不明確です。
これを解消するために、トレーニング データの精度を上げて、最もよく使われる設定が優先されるようにしました。また、こうした複雑なタスクのエクスペリエンスの改善にも、引き続き取り組んでいます。
今後の展望
設定エージェントのエクスペリエンスに関して、Windows Insiders プログラムにご参加の皆様からのフィードバックをお待ちしています。今後も引き続きエクスペリエンスの改良に取り組んでいきます。
これまでもお伝えしてきたとおり、Applied Science Group のチーム、WAIIA および WinData のパートナー チームの皆様のご尽力なしには、いずれの成果も達成することはできませんでした。ここにご紹介するご協力をいただいた皆様に感謝を申し上げます (敬称略)。Adrian Bazaga、Archana Ramesh、Carol Ke、Chad Voegele、Cong Li、Daniel Rings、David Kolb、Eric Carter、Eric Sommerlade、Ivan Razumenic、Jana Shen、John Jansen、Joshua Elsdon、Karthik Sudandraprakash、Karthik Vijayan、Kevin Zhang、Leon Xu、Madhvi Mishra、Mathew Salvaris、Milos Petkovic、Patrick Derks、Prateek Punj、Rui Liu、Sunando Sengupta、Tamara Turnadzic、Teo Sarkic、Tingyuan Cui、Xiaoyan Hu、Yuchao Dai。
Join the conversation