
※本ブログは、米国時間 6 月 6 日に公開された “Leveraging the power of NPU to run Gen AI tasks on Copilot+ PCs” の抄訳を基に掲載しています。
大規模言語モデル (LLM) は、その巨大なスケールと技術面での目覚ましい進化により、生成 AI イノベーションを象徴する存在となっています。しかし、何事も大きければ良いというものではありません。Microsoft Copilot などを支える LLM が幅広いタスクにおいて驚異的な能力を発揮する一方で、話題に上ることの少ない「小規模言語モデル (SLM)」は、生成 AI の活用範囲をリアルタイム処理やエッジ アプリケーションにまで拡大しています。SLM は、消費電力が少なく処理が高速なため、ローカル デバイス上で効率的に動作し、新たなシナリオやコスト モデルへの対応を可能にします。
SLM は CPU や GPU といった広く普及しているチップ上で動作しますが、Microsoft Surface のCopilot+ PC に搭載されているようなニューラル プロセッシング ユニット (NPU) 上でこそ、その真価を発揮します。NPU は機械学習ワークロードの処理に特化したプロセッサであり、ワットあたりのパフォーマンスと熱効率は CPU や GPU よりも優れています[1]。SLM と NPU を組み合わせることで、バッテリー駆動での作業やマルチタスクの処理においても、非常に強力な生成 AI ワークロードをノート PC 上で効率的に実行できます。
この記事では、ローカルでの効率的な推論の実行、ハードウェアの活用率向上、セットアップにおける複雑さの最小化に着目しながら、先日発売された Surface Laptop 13 インチに搭載されている Snapdragon® X Plus プロセッサ上で Qualcomm® AI Hub を使用して SLM を実行する方法を紹介します。ただし、これは数ある有効な手法のうちの 1 つにすぎません。具体的な説明に入る前に、まずは Copilot+ PC の NPU に SLM を展開する際に候補となるアプローチについて簡単に触れておきます。
- Qualcomm AI Engine Direct (QNN) SDK: この手順では、SLM を NPU で実行できるように QNN バイナリに変換する必要があります。Qualcomm AI Hub を使用すると、PyTorch モデル、TensorFlow モデル、または ONNX 形式に変換されたモデルを、Qualcomm AI Engine Direct SDK で実行可能な QNN バイナリに容易にコンパイルできます。また、Qualcomm AI Hub ではさまざまなコンパイル済みモデルを直接入手でき、175 種類以上の最適化済みモデルのコレクションからダウンロードして、アプリケーションに統合することができます。
- ONNX Runtime: マイクロソフトが開発した、ONNX 形式のモデルを実行するためのオープンソース推論エンジンです。Qualcomm Technologies の QNN Execution Provider (EP) を利用することで、主にモバイル向けや組み込み用途向けに、AI アクセラレーション ハードウェアを活用して Snapdragon プロセッサでの推論を最適化できます。
ONNX Runtime GenAI は、Transformer ベースのモデルを含む生成 AI タスク向けに最適化されたバージョンであり、大規模言語モデルなどのアプリケーションにおける高性能な推論の実現を目的としています。ONNX Runtime と QNN EP を組み合わせると、Copilot+ PC でモデルを実行することができるものの、生成 AI ワークロードに関しては一部の演算子がサポートされていません。ONNX Runtime GenAI はまだ NPU 向けに一般提供されておらず、現在はプライベート ベータ版です。この記事の投稿時点では一般提供の時期も不明です。今後のリリースに関する情報は、Git リポジトリ (microsoft/onnxruntime-genai: Generative AI extensions for onnxruntime (英語)) でご確認ください。 - Windows AI Foundry: Windows AI Foundry では、Copilot+ PC 向けに AI 対応機能や API を提供しています。Windows AI API 経由で推論を実行できる、Phi-Silica などの構築済みモデルも用意されています。さらに、クラウドからモデルをダウンロードし、Foundry Local を使用してローカル デバイス上で推論を実行することができます。この機能は現在プレビュー中です。Windows AI Foundry の詳細については、Windows AI Foundry | Microsoft Developer をご覧ください。
- AI Toolkit for Visual Studio Code (VS Code): 生成 AI アプリの開発を簡素化する VS Code 拡張機能であり、Azure AI Foundry カタログや Hugging Face (英語) などのカタログから最先端の AI 開発ツールやモデルが集約されています。このプラットフォームでは、複数のモデルをクラウドからダウンロードするか、ローカルで追加できます。現在は CPU 上での動作に最適化されたモデルが複数用意されており、DeepSeek-R1 を皮切りに、NPU ベースのモデルもまもなくサポートされる予定です。
各アプローチの比較
| 比較項目 | Qualcomm AI Hub | ONNX Runtime (ORT) | Windows AI Foundry | AI Toolkit for VS code |
|---|---|---|---|---|
| 利用可能なモデル | 幅広い AI モデル (画像認識、生成 AI、オブジェクト検出、音声)。 | 任意のモデルを統合可能。生成 AI タスク向けの NPU サポートと ONNX Runtime GenAI については、まだ一般提供されていない。 | Windows AI API 経由で Phi Silica モデルを利用可能。別のモデルをクラウドからダウンロードし、Foundry Local を使用してローカル デバイスで推論を実行できる。 | Azure AI Foundry や Hugging Face などからモデルを取得して利用可能。 現在、NPU 推論に関しては DeepSeek-R1 と Phi-4-mini のモデルのみがサポートされている。 |
| 開発の容易さ | 初期設定とエンドツーエンドのレプリケーションが完了すれば、API は使いやすい。 | セットアップが簡単で開発者にとって扱いやすい一方で、カスタム演算子のサポートが限られているため、ORT からすべてのモデルを展開できるわけではない。 | 最も簡単に導入できるフレームワーク。Windows App SDK に精通している開発者であれば容易に扱える。 | 直観的なインターフェイスで、プロンプトと応答を通じてモデルをテストできるため、試行やパフォーマンス検証を迅速に行える。 |
| プロセッサまたは SoC への依存の有無 | 依存する。Qualcomm Technologies のプロセッサのみをサポート。デバイス上の SoC 用にモデルをコンパイル、最適化する必要がある。対応しているチップ セットのリストが提供されており、最終的な .bin ファイルは個別の SoC に特化したものとなる。 | QNN EP の HTP バックエンドには制限があり、現在は量子化されたモデルと静的形状モデルのみがサポートされている。 | 依存しない。SoC とは独立して動作するツールであり、広範な Windows Copilot Runtime (現在は Windows AI Foundry に名称変更) フレームワークの一部。 | モデルによって異なる。デバイス上で簡単に展開でき、モデルのダウンロードと推論も容易に行える。 |
この記事を執筆している時点で調べたところ、現在利用可能なソリューションの中では Qualcomm AI Hub が最も使いやすく、サポートも充実していました。それに対して、他のフレームワークの大多数がまだ開発段階にあり一般提供されていません。
それでは、Qualcomm AI Hub を使用して小規模言語モデル (SLM) を実行する方法を掘り下げる前に、Qualcomm AI Hub について理解しておきましょう。
Qualcomm AI Hub とは
Qualcomm AI Hub は、画像処理、音声処理、音声認識、テキスト分析用の AI モデルをエッジ デバイスに容易に展開できるようにするためのプラットフォームです。CPU、GPU、NPU といった特定のターゲット ハードウェアに対して、数分でモデルをアップロード、最適化、検証することができます。PyTorch や ONNX で開発されたモデルは自動的に変換され、TensorFlow Lite、ONNX Runtime、Qualcomm AI Engine Direct などのフレームワークを使用してデバイス上で効率的に実行できるようになります。Qualcomm AI Hub では 100 種類を超える最適化済みモデルのコレクションにアクセスできるほか、GitHub と Hugging Face で公開されているオープンソースの展開レシピも利用できます。また、クラウドでホストされている Snapdragon および Qualcomm プラットフォームを搭載した実際のデバイスで、これらのモデルをテストおよびプロファイリングすることも可能です。
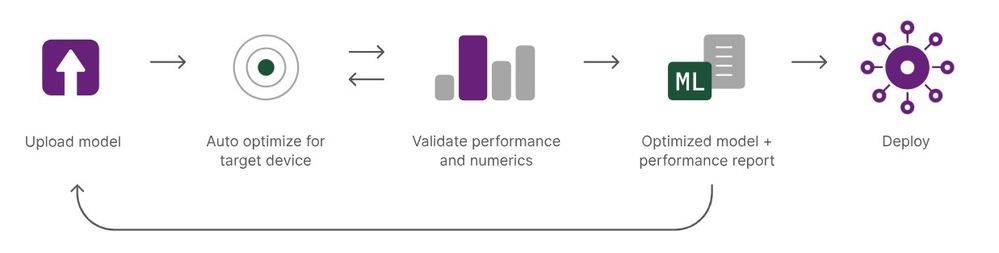
画像提供元: Qualcomm AI Hub
この記事では、Qualcomm AI Hub を使用してモデル用の QNN コンテキスト バイナリを取得し、Qualcomm AI Engine で実行する方法を紹介します。コンテキスト バイナリとは、個別の SoC に特化した展開メカニズムのことです。ある特定のデバイス用にコンパイルされた場合、そのモデルは同一のデバイスに展開されることが前提となります。このフォーマットはオペレーティング システムに依存しないため、同じモデルを Android、Linux、Windows に展開することができます。なお、コンテキスト バイナリは NPU 専用です。別のフォーマットでモデルをコンパイルする方法については、Qualcomm AI Hub ドキュメント サイトの「Qualcomm AI Hub の概要 (英語)」を参照してください。
ここからは、Qualcomm Snapdragon X Plus プロセッサと Hexagon™ NPU を搭載した Surface Laptop 13 インチ上で Qualcomm Al Hub を使用して、特定のハードウェアに最適化されたバイナリによって Phi-3.5 モデルを効率的に実行した事例について詳しく説明します。
Microsoft Surface エンジニアリング ケース スタディ: Surface Laptop 13 インチの Snapdragon X Plus で Phi-3.5 モデルをローカル実行する
このケース スタディでは、Snapdragon X Plus プロセッサを搭載した Surface Laptop 13 インチに Phi-3.5 モデルを実際に展開しました。ケース スタディを実施し記録をまとめた Surface DASH チームは、Surface デバイスへの AI/ML ソリューションの提供と、高度なテレメトリによるデータ主導のインサイト生成を専門としています。チームは Qualcomm AI Hub 使用して、ターゲット SoC に合わせて事前にコンパイルされた QNN コンテキスト バイナリを取得し、ローカルでの推論を効率的に実行できるようにしました。この手法により、ハードウェアを最大限に活用し、セットアップの複雑さを最小限に抑えることができます。
テスト デバイスには、Snapdragon X Plus プロセッサ搭載の Surface Laptop 13 インチを使用しました。以下に示す手順は Snapdragon X Plus プロセッサに適用されるものですが、他の Snapdragon X シリーズ プロセッサやデバイスでも同様です。それ以外のプロセッサの場合は、Qualcomm AI Hub から目的のモデルの異なるバージョンをダウンロードする必要があります。この手順を進める前に、デバイス マネージャーを開いて [Neural processors] に移動し、お使いの NPU のメーカーとモデルを確認してください。
Visual Studio Code と Python (3.10、3.11、3.12) も使用しました。以下の手順ではバージョン 3.11 を使用したので、同じバージョンの使用を推奨しますが、それ以降のバージョンの Python を使用しても違いはないと思われます。
また、作業を始める前に Python で新しい仮想環境を作成することをお勧めします。新しい仮想環境の作成手順は以下のページでご確認ください。
https://code.visualstudio.com/docs/python/environments?from=20423#_creating-environments (英語)
大まかな手順としては、初めに構成ファイルと bin ファイルを格納するための「genie_bundle」というフォルダーを作成します。お使いの NPU 専用の QNN コンテキスト バイナリをダウンロードして、構成ファイルを genie_bundle フォルダーに保存します。続いて、QNN SDK から .dll ファイルを genie_bundle フォルダーにコピーします。最後に、genie-sdk を介して Phi-3.5 に必要な形式でテスト プロンプトを実行します。
詳細なセットアップ手順
ステップ 1: ローカル開発環境をセットアップする
QNN SDK をダウンロード: Qualcomm 公式サイト Qualcomm Neural Processing SDK | Qualcomm Developer (英語) にアクセスし、[Get Software] をクリックして QNN SDK をダウンロードします (既定では最新バージョンの SDK がダウンロードされます)。今回のケース スタディでは最新バージョン (2.34) を使用しました。アクセスの際に Qualcomm の Web サイトでアカウントの作成が必要になる場合があります。
ステップ 2: Qualcomm AI Hub のモデル コレクションから QNN コンテキスト バイナリをダウンロードする
- バイナリをダウンロード: Phi-3.5-mini-instruct モデルのコンテキスト バイナリ (.bin ファイル) をダウンロードします (Phi-3.5 コンテキスト バイナリのダウンロード リンク)。
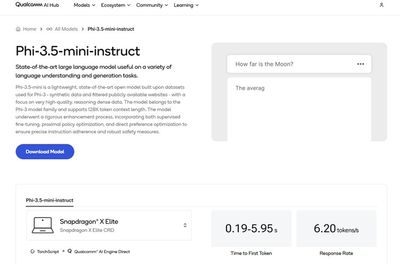
画像提供元: Qualcomm AI Hub
- AI Hub Apps リポジトリをクローン: Genie SDK (Qualcomm AI Direct Engine 上に構築された生成 AI ランタイム) を使用し、https://github.com/quic/ai-hub-apps (英語) で提供されているサンプルを利用します。
- コードに合わせてフォルダーを構成: AI Hub Apps リポジトリをクローンしたフォルダーの外側に「genie_bundle」というフォルダーを作成します。この genie_bundle フォルダーに、AI Hub Apps のサンプル リポジトリから必要な構成ファイルを選択してコピーします。
「genie_bundle」というフォルダーを作成
ステップ 3: 構成ファイルをコピーし、各ファイルを編集する
- ai-hub-apps から genie_bundle フォルダーに構成ファイルをコピーします。ここでは 2 つの構成ファイルが必要になります。以下の PowerShell スクリプトを使用して、前の手順で作成したローカルの genie_bundle フォルダーに、リポジトリの構成ファイルをコピーします。このとき、構成ファイルだけでなく、HTP バックエンド構成ファイルもリポジトリからコピーする必要があります。
1# ソースのパスを定義 2$sourceFile1 = "ai-hub-apps/tutorials/llm_on_genie/configs/htp/htp_backend_ext_config.json.template" 3$sourceFile2 = "ai-hub-apps/tutorials/llm_on_genie/configs/genie/phi_3_5_mini_instruct.json" 4 5# ローカル フォルダーのパスを定義 6$localFolder = "genie_bundle" 7 8# ローカル フォルダーを基にコピー先のファイル パスを定義 9$destinationFile1 = Join-Path -Path $localFolder -ChildPath "htp_backend_ext_config.json" 10$destinationFile2 = Join-Path -Path $localFolder -ChildPath "genie_config.json" 11 12# ローカル フォルダーが存在しない場合は作成 13if (-not (Test-Path -Path $localFolder)) { 14 New-Item -ItemType Directory -Path $localFolder 15} 16 17# ファイルをローカル フォルダーにコピー 18Copy-Item -Path $sourceFile1 -Destination $destinationFile1 -Force 19Copy-Item -Path $sourceFile2 -Destination $destinationFile2 -Force 20Write-Host "Files have been successfully copied to the genie_bundle folder with updated names." - ファイルをコピーした後、コピーしたテンプレート ファイルに設定されているパラメーターの既定値を変更する必要があります。
- コピー先の HTP バックエンド ファイルを編集し、soc_model と dsp_arch の値を自分の構成に合わせて変更します。
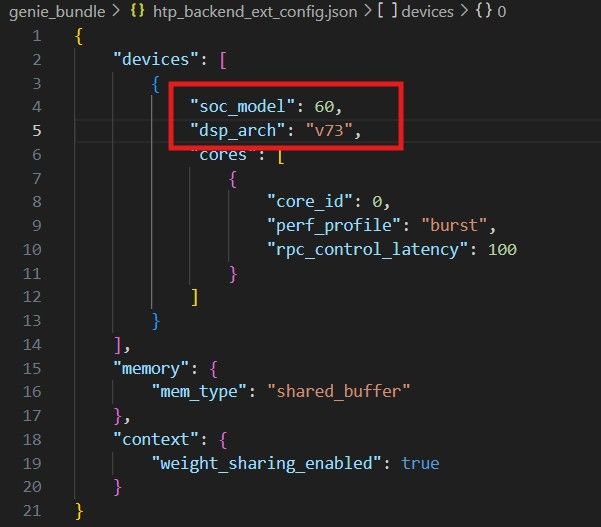
HTP バックエンド構成ファイルの soc_model と dsp_arch を更新
- genie_config ファイルを編集し、前の手順でダウンロードした Phi-3.5 モデルのバイナリを含めます。
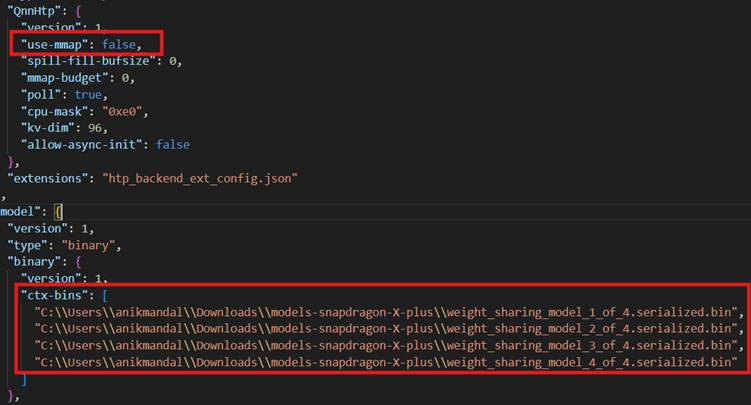
ダウンロードしたバイナリ ファイルに合わせて場所を更新し、パラメーター「use-map」を必ず false に設定する
- コピー先の HTP バックエンド ファイルを編集し、soc_model と dsp_arch の値を自分の構成に合わせて変更します。
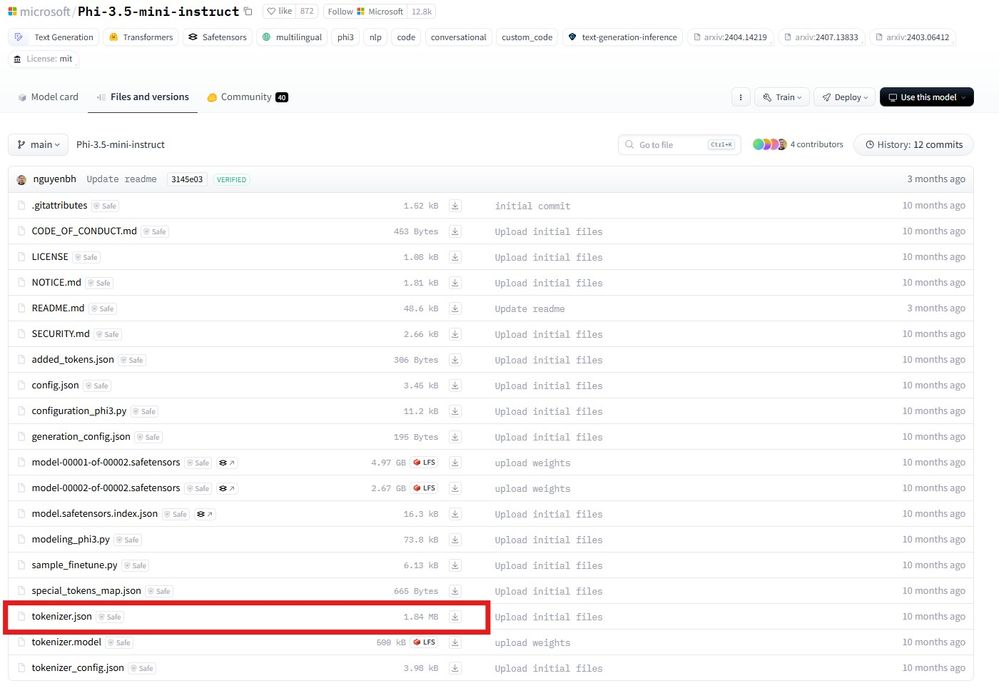
ステップ 4: Hugging Face からトークナイザー ファイルをダウンロードする
- Hugging Face の Web サイトにアクセス: Web ブラウザーを開き、https://huggingface.co/microsoft/Phi-3.5-mini-instruct/tree/main (英語) に移動します。
- トークナイザー ファイルを探す: Hugging Face のページで、Phi-3.5-mini-instruct モデルのトークナイザーを見つけます。
- ファイルをダウンロード: ダウンロード ボタンをクリックして、トークナイザー ファイルを自分のコンピューターに保存します。
- ファイルを保存: genie_bundle フォルダーに移動し、ダウンロードしたトークナイザーファイルをそこに保存します。
注: Phi-3.5-mini-instruct モデルの tokenizer.json ファイルには、出力において空白による単語の区切りが行われないという問題があります。これを解決するためには、tokenizer.json ファイルの 192 ~ 197 行目を削除します。
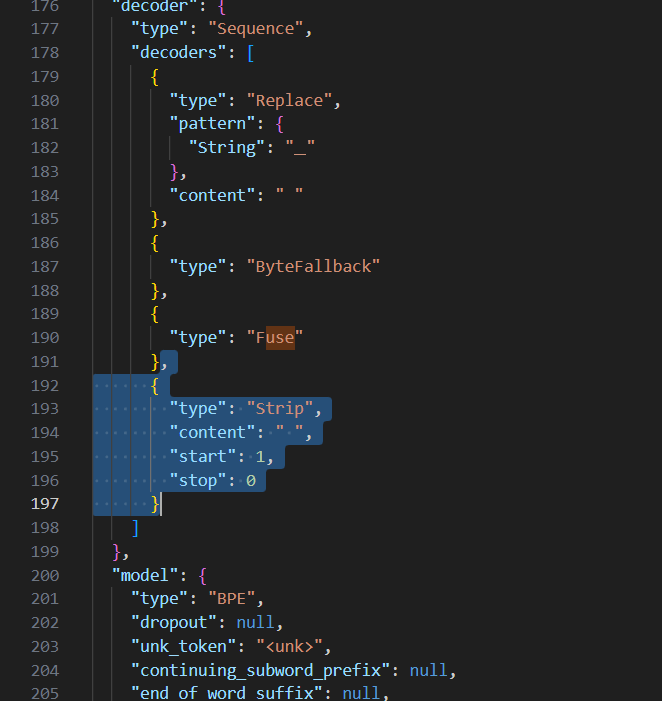
Hugging Face のリポジトリからトークナイザー ファイルをダウンロード (画像提供元: Hugging Face)
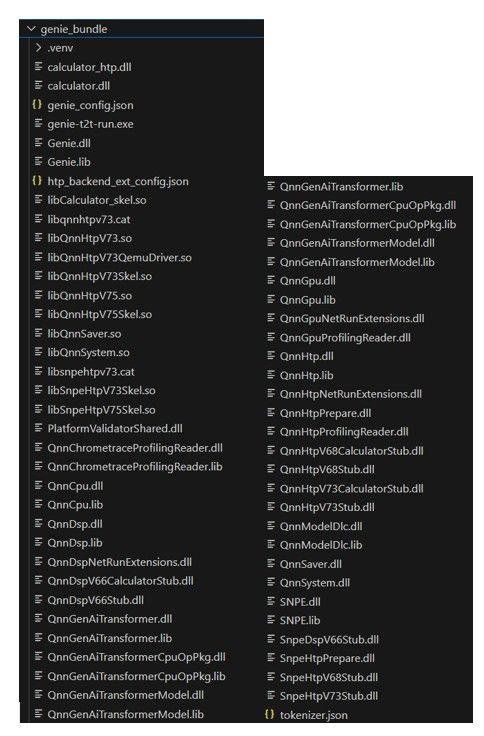
ステップ 5: QNN SDK からファイルをコピーする
- QNN SDK フォルダーを探す: ステップ 1 で QNN SDK をインストールしたフォルダーを開き、必要なファイルを見つけます。以下に示すフォルダーからファイルをコピーします。正確なフォルダー名は、SDK のバージョンによって異なる場合があります。
- <QNN-SDK ルート フォルダー>/qairt/2.34.0.250424/lib/hexagon-v75/unsigned
- <QNN-SDK ルート フォルダー> /qairt/2.34.0.250424/lib/aarch64-windows-msvc
- <QNN-SDK ルート フォルダー> /qairt/2.34.0.250424/bin/aarch64-windows-msvc
- genie_bundle フォルダーに移動し、コピーしたファイルを貼り付けます。
ステップ 6: テスト プロンプトを実行する
-
- ターミナルを開く: ターミナルまたはコマンド プロンプトで genie_bundle フォルダーに移動します。
- コマンドを実行: 以下のコマンドをコピーしてターミナルに貼り付けます。
1./genie-t2t-run.exe -c genie_config.json -p "<|system|>\nYou are an assistant. Provide helpful and brief responses.\n<|user|>What is an NPU? \n<|end|>\n<|assistant|>\n" - 出力を確認: コマンドを実行すると、ターミナルにアシスタントからの応答が表示されます。
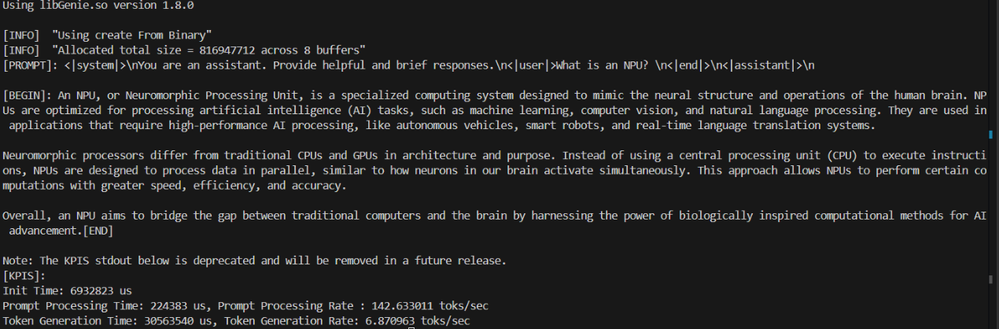
今回のケース スタディでは、Hexagon NPU と Qualcomm AI Hub を活用して、Copilot+ PC に Phi-3.5 のような小規模言語モデル (SLM) を展開するプロセスを紹介しました。また、特定のハードウェアに特化したバイナリを使用してローカルで推論を実行する際に必要なセットアップ手順、ツール、構成について概説しました。さまざまな展開手法が確立されつつある中で、このアプローチは、エッジ デバイス上で直接生成 AI を効率的かつスケーラブルに実行するための現実的な選択肢であると言えます。
Snapdragon® および Qualcomm® ブランドの製品は、Qualcomm Technologies, Inc. またはその子会社の製品です。Qualcomm、Snapdragon および Hexagon™ は、Qualcomm Incorporated の商標または登録商標です。