
Surface で NPU を活用する:「Hello World」モデルの実行例
※ 本ブログは、米国時間 2024/5/23 に公開された “Unlocking the power of NPU on Surface: Our “Hello World” journey” の抄訳です。
皆様が日々使用しているデバイスが、複雑なタスクを簡単にこなせる強力な AI デバイスに変わるとしたらどうでしょうか? 最先端の NPU (ニューラル プロセッシング ユニット) を搭載した新しい Surface 製品群の登場により、これが現実になります。これらの専用ハードウェア コンポーネントにより、手持ちのデバイスの AI 性能に革命がもたらされ、前例のないスピード、効率性、プライバシー確保が実現されます。
NPU とは
NPU アーキテクチャは行列演算に最適化されており、ニューラル ネットワークの層を高速に実行し、驚くべき効率性で推論を加速します。AI ワークロードを CPU や GPU からオフロードすることで、NPU は消費電力を削減し、デバイスのパフォーマンスの向上、バッテリー持続時間の延長、熱管理の改善を可能にします。NPU はデバイス上でローカルにモデルを実行するため、リアルタイム アプリケーションのレイテンシが軽減されるほか、データがデバイス内に保持されるため、開発者がデータ プライバシーを制御しやすくなります。
詳細については、以下の Qualcomm のリソースをご覧ください。
はじめに
Surface 開発チームのデータ サイエンティストとして、私たちはこの新しい PC で NPU を独自のモデルやアプリケーションに活用できるようになることを心待ちにしていました。詳細に入る前に、まずは基本を押さえていきましょう。NPU にはどのように接続し、どのようにモデルを実行できるかについてです。この記事では、具体的な例として実際に私たちが NPU 上で「Hello World」モデルをどのように実行したかについて紹介します。ぜひ皆様もお試しください。畳み込みニューラル ネットワーク (CNN) の典型的な手書き数字分類モデルを NPU に展開する手順を説明します。
モデルを構築する
「Hello World」ニューラル ネットワーク モデルの作成にあたっては、公開されている MNIST データセットを使用しました。MNIST データセットには手書き数字の画像が含まれています (MNIST – Torchvision のメイン ドキュメント (英語))。Web 上には分類モデルのトレーニング方法を説明するブログ記事が多数あります (私たちが使用したのは PyTorch での MNIST 手書き数字分類 – Nextjournal (英語) です)。他のトレーニング済みモデルを使用することもできます。
ONNX に変換する
PyTorch モデルは NPU 上で直接実行できないため、PyTorch 関数の “torch.onnx.export” を使用してモデルを ONNX 形式に変換しました。ONNX は、さまざまなハードウェア プラットフォームや実行環境でモデルを実行するためのファイル形式です。モデルを ONNX に変換する詳細な手順については、PyTorch から ONNX にモデルをエクスポートする (英語) をご覧ください。TensorFlow などのフレームワークを使用する場合も、同様の変換プロセスが必要になります。
ヒント: Surface の NPU は動的軸をサポートしていません。そのため、ONNX 形式にエクスポートする場合は、バッチ サイズを含むすべてのインプットの次元を修正する必要があります。PyTorch モデルを ONNX 形式に変換するために使用したコードの一部は以下のとおりです。

NPU を展開する開発環境を設定する
モデルを ONNX に変換した後、NPU 上でモデルを実行するための開発環境を設定しました。QNN Execution Provider (英語) については、ONNX Runtime のドキュメントに従いました。
ヒント
- ソフトウェアのバージョン: 量子化は x64 版の Python を使用して行う必要があります。仮想環境で実行することを推奨します。モデルを実行するには、Python(ARM) 3.11.x と NumPy 1.25.2 を使用します。NumPy をインストールする前に、Microsoft Visual C++ Build Tools をインストールし、適切なコンポーネントを選択してください。
- デバイス固有のコード: ONNX Runtime セッションの開始時に、Hexagon Tensor Processor (HTP) アーキテクチャの値を指定します。Copilot+ PC、Surface Pro、Surface Laptop に搭載の Qualcomm® Hexagon™ NPU の場合、コードは 73 です。このコードのマッピングは公開されていないため、メーカーからのサポートが必要な場合があります。
- ライブラリ ファイル: 共有ライブラリ ファイル (.so) がシステム ディレクトリだけでなく、同じプロジェクト フォルダーにコピーされていることを確認してください。
モデルを量子化する
次に、モデルを量子化し、32 ビット浮動小数点モデルを 8 ビット整数モデルに変換しました。量子化は、モデルの精度と計算効率のバランスを取るものです。量子化フレームワークは大きく分けて、動的量子化と静的量子化の 2 種類があります。
Copilot+ PC、Surface Pro (第 11 世代)、Surface Laptop (第 7 世代) に搭載の Qualcomm Hexagon NPU は、静的量子化をサポートしています。静的量子化では、重みとアクティベーションの両方が展開前に量子化されます。
前処理と量子化については、QNN のドキュメント ONNX モデルの量子化 (英語) に従いました。静的量子化の手法で最適な量子化パラメーターを決定するために、代表的なデータ サンプルを使用してキャリブレーション データを作成しました。パラメーターはドキュメントのサンプルにある既定のものを使用しました。アクティベーションは uint16、重みは uint8 です。これで、量子化された ONNX モデルを NPU で実行する準備ができました。
ヒント: サポート対象の ONNX 演算子。このブログ記事の執筆時点では、量子化できない演算子も存在します。NPU アクセラレーションをフル活用するには、すべての層が QNN との互換性があることを確認してください。サポート対象の演算子セットについては、サポート対象の ONNX 演算子 (英語) を確認してください。
モデルを実行する
モデルを NPU 上で実行するために、ONNX Runtime 推論を開始しました。各種パラメーターは、特定のユース ケースに合わせて設定オプション (英語) のように設定できます。

モデルのインターフェイスは、ユーザー フレンドリーになるようにシンプルな Flask アプリを作成しました。モデルを実行するたびにタスク マネージャーで NPU のリソース使用量を観察し、NPU が実際に使用されていることを確認しました。
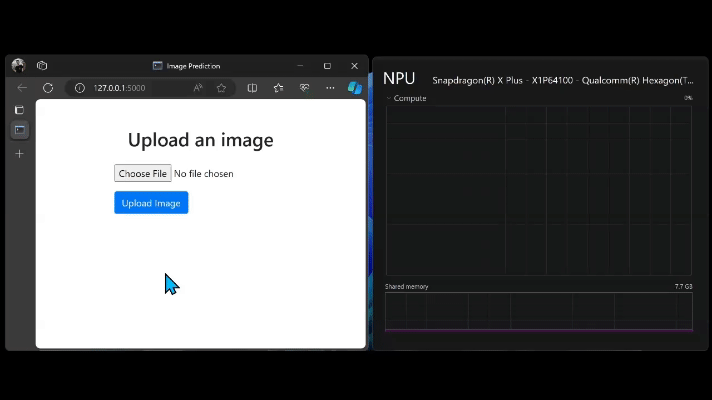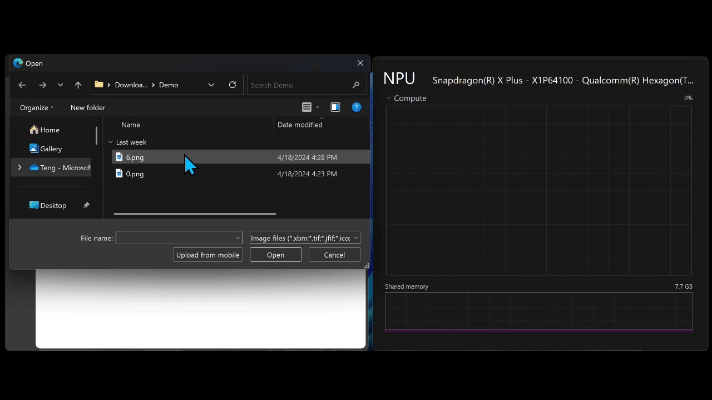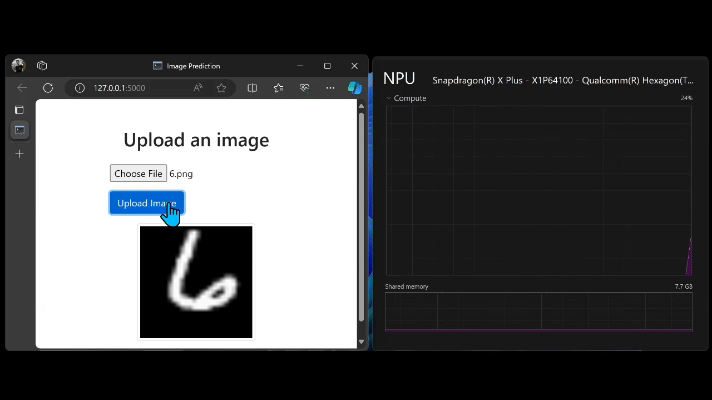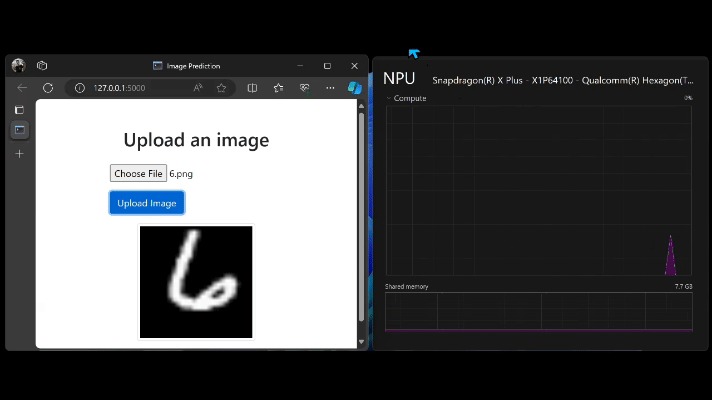
まとめ
ここでは実際に NPU で「Hello World」モデルを実行した方法について説明してきましたが、決して簡単な道のりではありませんでした。その過程では多くの学びがあり、特に、量子化の手順では精度と効率のバランスを取るための工夫が重要でした。これは、今後のアプリケーション開発においても重要な検討事項になるでしょう。
もう 1 つの大きな学びとしては、大規模ニューラル ネットワーク モデルや、音声、視覚、言語のデータ型に対する推論などのタスクには NPU が最適であり、他のタスクには CPU や GPU が適しているということです。開発中に複数のモデルをテストするのと同じように、今後のプロジェクトでは、さまざまな実装方法を試し、推論時間や消費電力の観点から最もパフォーマンスが高い実装方法を判断する計画です。
今回のテストは、今後の展開を検討するうえで非常に大きなモチベーションとなりました。NPU を活用することで、さらに優れた Surface デバイスとエクスペリエンスを構築できると信じています (そして、皆様がどのように活用されるのかも楽しみです)。
マイクロソフトの応用科学グループ、Qualcomm、ONNX などの協力を経て、この分野は急速な成長を見せています。多くのライブラリがオープンソース化されているため、これらのアセットは今後さらに改良されていくはずです。ぜひ一緒に NPU の無限の可能性を切り拓きましょう。皆様ならどのように使いますか?
Join the conversation