
LLM はウォール街の言葉を “読む” ことはできるが、その真意を理解できるのか? ファイナンシャル IQ のベンチマーク評価

※本ブログは、米国時間 2025 年 6 月 16 日に公開された、”LLMs can read, but can they understand Wall Street? Benchmarking their financial IQ” を基に掲載しています。
Dominick Kubicaa+、Dylan T. Gordona+、Nanami Emuraa+、Derleen Sainia+、Charlie Goldenberga+*
a Department of Business Analytics, Santa Clara University – Leavey School of Business (Santa Clara, California 95053, United States)
+ 上記の執筆者は同等に貢献しています。
この研究は、Microsoft MCAPS AI Transformation Office の Juhi Singh と Bonnie Ao 主導のもと、マイクロソフトが出資した Capstone プロジェクトの一環として実施されました。
AI が専門分野のワークフローにますます組み込まれるようになれば、金融などの高リスク分野においても生成 AI の役割は広がりを見せることが考えられます。金融・財務分野で使われる言語には、将来予測に関する記述や曖昧な表現、現行モデルに異を唱える繊細な言葉などが含まれるため、独特の複雑さがあります。その種のニュアンスを今日の大規模言語モデル (LLM) が理解することはできるのでしょうか?
そうした疑問をきっかけに、サンタクララ大学とマイクロソフトの AI Transformation チームは共同研究プロジェクトを推し進めることになりました。このプロジェクトでは、財務センチメント分析において LLM が従来の自然言語処理 (NLP) ツールのパフォーマンスを上回ることができるかどうかを評価しました。また、四半期決算説明会など実際の財務報告に採用された場合に、有益なインサイトを生成できるかどうかも確認しました。
この取り組みは次の 3 ステップで進められました。
- 標準化された財務データセットで LLM と従来の NLP ツールのベンチマーキングを実施する
- これらのモデルをマイクロソフトの四半期決算説明会のトランスクリプトに適用し、事業部門別にセンチメントを分析して、そのトランスクリプトから抽出できるインサイトを深く理解する
- 結果を分析して最適化の機会を特定し、センチメント分析が実際の株価パフォーマンスとどの程度相関関係があるかを評価する
結果は今後に期待できるものであり、驚くべきものでもありました。微妙なニュアンスのセンチメントの把握において、LLM は従来のツールのパフォーマンスを大幅に上回ったものの、依然として課題の残る部分もありました。この記事では、このベンチマーキング プロセス、実世界での調査結果、Microsoft Copilot などのツールを強化するための推奨事項について紹介します。
ベンチマーキングでモデルの精度を評価する
LLM のパフォーマンスと従来の NLP ツールのパフォーマンスの違いを評価するには、客観的なベンチマーキングを行うことが不可欠です。まず、標準的な評価を実施し、各モデルが財務テキスト上のセンチメントをどの程度正確に解釈できるかを測定しました。この比較は、金融・財務分野の言語の複雑さを考慮しながら、各モデルがどの程度効果的にトーンやニュアンスを捉えられるかに注目したものであり、その分析結果はツールの選択や今後のモデル開発に活用できます。
この精度評価には、アールト大学の研究者が開発した Financial PhraseBank (英語) データセットを使用しました。このデータセットは金融・財務や収益関連のニュースの見出しで構成され、市場センチメントに基づいて「肯定的」「中立」「否定的」のラベル付けがされています。次の 9 つのモデルを比較しました。
- LLM ベース/クラウド プラットフォーム: Microsoft Copilot Desktop App、Microsoft 365 版の Copilot、Copilot App Online、ChatGPT – 4o、Google Gemini 2.0 Flash
- クラウドベースの NLP サービス: Azure Language AI
- Python ライブラリ: FinBERT (Python ライブラリ経由の Transformer モデル)、NLTK、Textblob (Microsoft Copilot 365)
各モデルはこのデータセットの同じ文章を分類しました。金融・財務関連の文章は、書式の一貫性を確保するために、従来の NLP ライブラリ用に前処理されました。LLM ベースのツール用には、実世界での適用を反映するために、同一のプロンプトを使用しました。各モデルが一文ごとにセンチメントを返した後、事前にラベル付けされたデータセットに対する正しい分類の割合である精度を測定しました。Copilot Desktop App と Copilot Chat のインターフェイスは、ローカルで実行する場合も Web 経由でアクセスする場合も「Think Deeper」機能が使用されましたが、Microsoft 365 では「Think Deeper」機能を使用できませんでした。
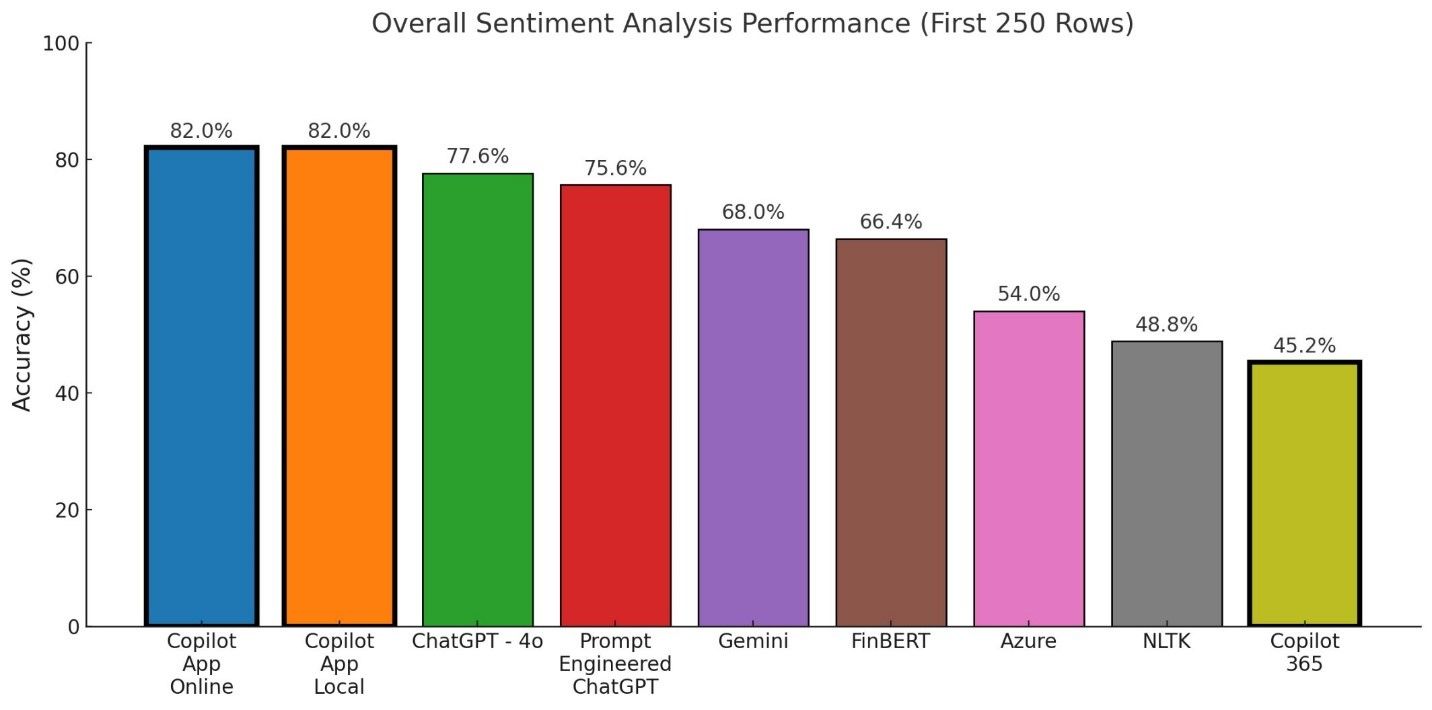
ベンチマーキングの結果、センチメント分析の精度にはモデル間で大きな違いがあることがわかりました。Copilot App (オンラインとローカルの両方) はモデルの中で 82.0% という最も高い精度を示しました。次いで、ChatGPT 4o (77.6%)、プロンプトを最適化した ChatGPT (75.6%)、Gemini (68.0%) と続きました。注目すべきは、前処理していない文章を使用した LLM が、ニュアンスや曖昧な表現の検知で他よりも高いパフォーマンスを示した点です。
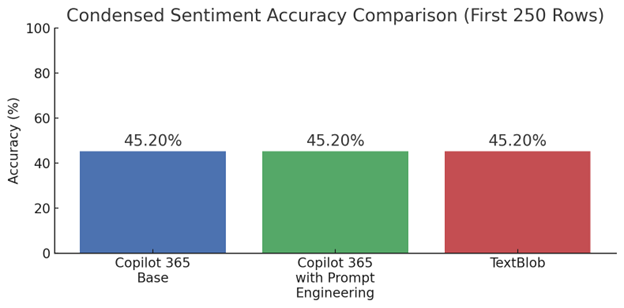
このベンチマーキングでは、Microsoft 365 版の Copilot の精度が他の LLM センチメント モデルよりも低くなりました。調査したところ、Copilot Desktop App と Web でホスティングされた Chat は、LLM ベースの計算能力に依存していた一方、Copilot 365 は主要なセンチメント分析ツールとして既定で TextBlob Python ライブラリを使用していたことが判明しました。しかし、Copilot 365 が主に Microsoft 365 スイートの主要な機能を最適化、拡張する目的で設計されていることを考えれば、当然の結果とも言えます。
初期の研究では Microsoft 365 Copilot に焦点を当てたため、センチメント分析の結果は範囲と精度が限定されたものになりました。しかし、ローカルとオンラインの両方の Copilot App で追跡調査をしたところ、より優れたパフォーマンスを発揮することがわかりました。いずれのバージョンでも「Think Deeper」モードで 82% の精度を達成し、すべての評価対象モデルの中で最も高いベンチマークを記録しました。この結果は、能力を評価する際、異なる Copilot インターフェイスは区別することが重要であることを示しています。
アプリ版は高いパフォーマンスを示しましたが、使いやすさとアクセシビリティの点で懸念が残っています。現時点では、Microsoft 365 版の Copilot App とスタンドアロンの Copilot App のパフォーマンスと機能の違いについて、ユーザーに十分な情報が提供されていません。それらの背景情報がなければ、どのケースでどのモデルを使うべきか判断できない可能性があります。
評価中、Copilot のすべてのバージョンで、構造化されたデータ (CSV ファイルなど) を処理する際に特別な注意を払う必要がありました。正確な解釈を行うために、多くのケースでデータを手動でプレーン テキストに変換する必要があったほか、ラベルの書式設定や整理などのタスクの後処理中にハルシネーションのパターンが見られました。たとえば、センチメント ラベルを小文字に変換するよう指示すると、一部のモデルは予期せぬ結果や一貫性のない結果を返し、評価で不一致と判定されました。
こうした問題がある一方で、Microsoft 365 Copilot は、要約やトランスクリプトのセグメンテーションといった自然言語の周辺タスクで優れたパフォーマンスを発揮しました。これは、センチメントの分類が補助的な機能であっても、企業の幅広いユース ケースに対応できる価値があることを示しています。
マイクロソフトは、Copilot の基盤となるツールの透明性と文書化能力を強化することで、ユーザー エクスペリエンスを向上できると考えています。さまざまなコンテキストで使用されるモデルやエンジンの明確な情報を提供することで、ユーザーはシステムの最適な適用方法をすぐに把握できるようになります。さらに、マイクロソフトが仮に Microsoft 365 Copilot 内の緊密なモデルの統合を阻む現在の規制を緩和した場合、財務センチメント分析などの専門分野でパフォーマンスの大幅な向上が期待できます。
全体として LLM は、曖昧なセンチメントや微妙なニュアンスのセンチメントの識別で、従来のセンチメント エンジンよりも優れたパフォーマンスを発揮しました。ChatGPT と Gemini は高い成果を示し、FinBERT は財務固有のケースで特に効果的でした。しかし、Copilot App のパフォーマンスが際立っていることから、マイクロソフトが開発したモデルが非常に優れていることが裏付けられました。Microsoft 365 環境のこれらの機能へのアクセスを拡大すれば、複雑で難しいニュアンスを持つ財務データの理解をさらにサポートできるようになります。
実世界への応用: 事業部門のセンチメントと株価予測の関係
標準化されたデータセットを使用した LLM のベンチマーキングにより、モデルの精度に関する有益なインサイトが得られましたが、私たちはこれらのツールがベンチマーキングの結果を実際の財務環境で実用的なインサイトに変換できるかどうかを評価したいと考えました。具体的には、決算説明会のトランスクリプトに含まれる事業部門のセンチメントがさらなるビジネス上のインサイトや競合データを生み出し、株価の変動との相関関係を示すことができるのか、という点です。
まず、Copilot を使用してマイクロソフトの四半期決算説明会のトランスクリプトを切り離し、事業部門別に分類しました (Devices、Dynamics、Gaming、Office Commercial、Search & News Advertising、Server Products and Cloud Services、Q&A、Overall Sentiment)。各セグメントは ChatGPT 4o を使って処理し、事業部門レベルでセンチメントを評価しました。ChatGPT-4o がセンチメント分析ツールに選ばれたのは、出力に一貫性があり、標準化された単一の Python ワークフローで数四半期分のトランスクリプトを効率的に処理できるためです。Copilot のセンチメントの精度が最も高かったものの、API アクセスがなく、入力を手動に頼ることになるため、大規模な分析には向かないという結論に至りました。それに迫る ChatGPT-4o の高いパフォーマンスと優れたアクセシビリティを考慮した結果、ChatGPT-4o が分析を実行するうえで最も現実的な選択肢となりました。
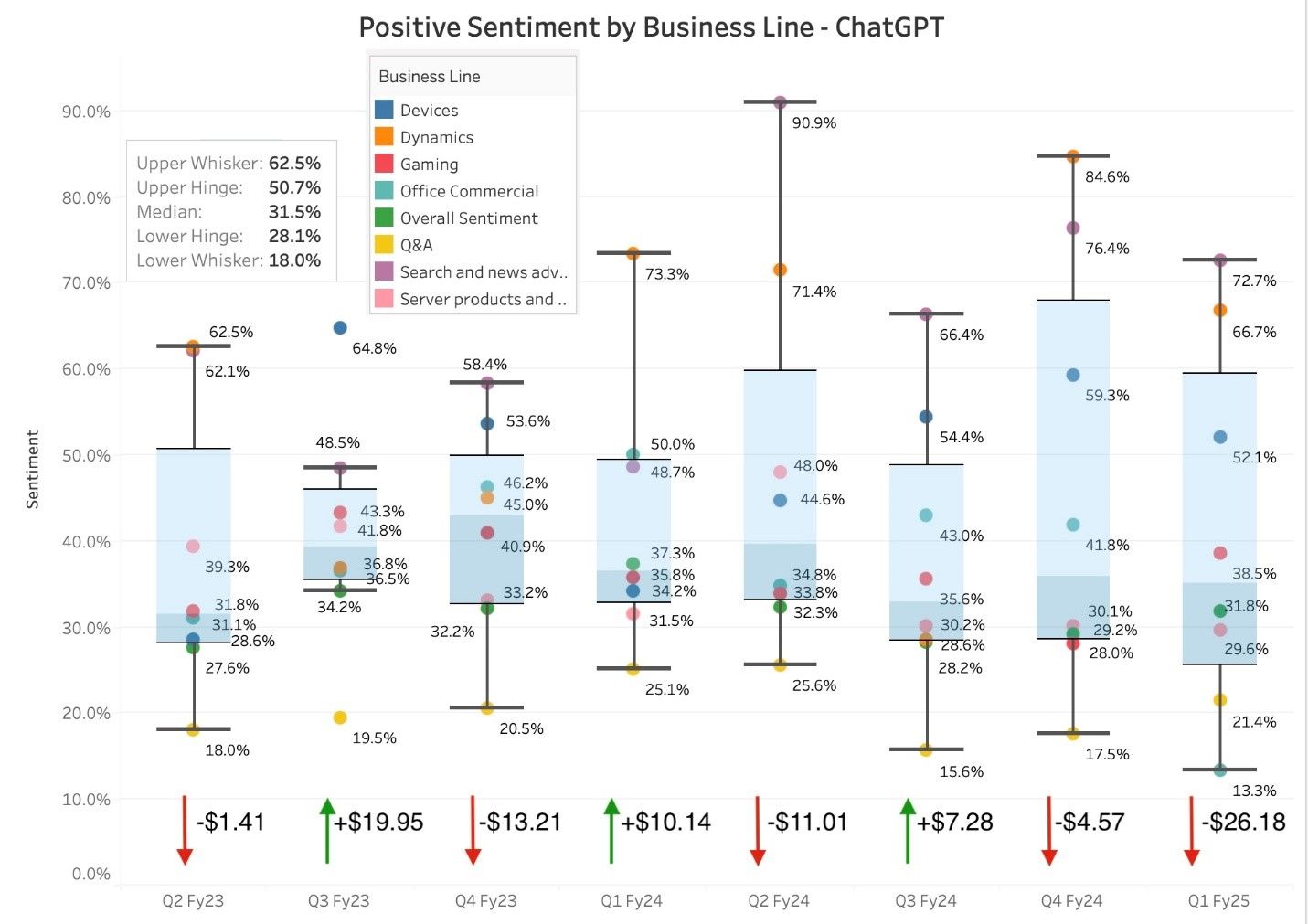
この箱ひげ図では、四半期ごとの青い網掛けのボックスがデータの四分位範囲を示しており、黒い横線は外れ値のないセンチメントの最大値と最小値を表しています。図の下部にある矢印は、各四半期決算説明会の翌日の株価の上昇と下落を示しています。
トランスクリプト全体のセンチメント分析では、株価の変動に関するインサイトは限定的でしたが、事業セグメント別のセンチメント分析では、見落とされがちな重要なパターンが見えてきました。たとえば、2025 年第 1 四半期の「Search and News Advertising」セグメントの非常に肯定的なセンチメントは、決算説明会後の著しい株価下落と関係していました。反対に、2023 年第 3 四半期の「Devices」では肯定的なセンチメントが急上昇したのに続いて、マイクロソフトの株価が大幅に上昇しています。これらは、特定の事業セグメント内のセンチメントが、各決算説明会の全体的なトーンよりも市場の反応に大きな影響を与える可能性があることを示唆しています。
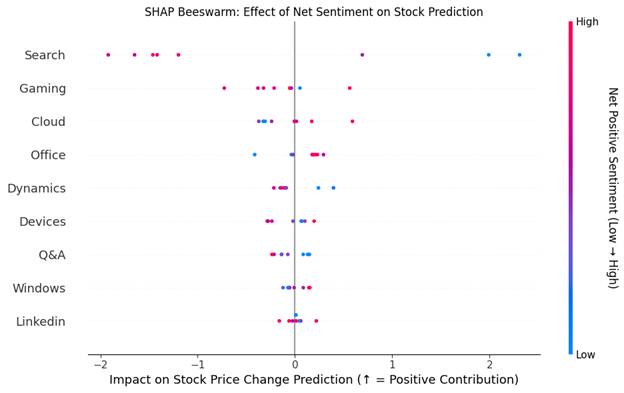
このセンチメントと株価変動の潜在的な因果関係をさらに深く理解し、パターンを可視化するために、SHAP (SHapley Additive exPlanations) の蜂群図を使用して、株価変動にセンチメントの方向性を対応付けました。このグラフの各点は、特定の四半期内の事業セグメントを表しています。赤い点は非常に肯定的なセンチメント、青い点は否定的なセンチメントを示しています。横軸は SHAP 値で、各事業部門のセンチメントがモデルの株価変動予測にどの程度寄与しているかを示しています。ゼロから遠い値ほど影響が大きいということです。
重要なのは、「Search and News Advertising」の赤い点が左側に偏っていることです。これは、肯定的なトーンが投資家に疑念を抱かせるものになったり、過度な楽観主義を示すものと捉えられたりすることで、投資家の売却行動につながるという私たちの仮説を補強するものです。
この逆相関関係により、トランスクリプト内の肯定的なセンチメントが必ずしも外部や投資家の肯定的なセンチメントにつながるとは言えない、という深い洞察が得られました。Gaming や Q&A などのセグメントでも同様にセンチメントの逆転が見られ、楽観的な声明の後に株価の下落が起きていました。これらのケースは、センチメント分析の中核的な課題を示しています。つまり、トーンだけでは投資家のセンチメントの信頼できる予測因子にならないということです。投資家の反応は、コンテキスト、期待、幅広い市場のストーリーを加味して決まる傾向にあります。
結論として、トランスクリプトを事業部門別に分類することは重要なインサイトを明らかにするための鍵であり、それによって、ざっくりとした分析から詳細な解釈へと向かわせることができます。LLM をワークフローに統合すると、予測精度とコンテキストに沿った理解を強化することが可能になります。株価変動についての最終的な結論はまだ出せていませんが、この調査結果は、LLM をその分野の専門知識と組み合わせることがセンチメントのパターンを明らかにするのに効果的であり、そこから有望な分野を特定し、掘り下げることが可能であることを示しました。
調査結果と最適化のための推奨事項
今回のベンチマークの結果をマイクロソフトの決算説明会のケース スタディと合わせて見直したところ、次のような重要なインサイトが浮かび上がりました。
- LLM は、財務センチメント分析において、特につなぎ言葉や繊細な表現の検出時に、従来のツールよりも明らかに高いパフォーマンスを発揮しました。
- 従来のモデルは積極的なテキスト クリーニングを必要としますが、それによってニュアンスが失われることがあります。LLM ではより多くのつなぎ言葉のコンテキストを活用することができました。
- LLM は強みがある一方、精度が 85% を超えることはありませんでした。財務エキスパートなら、独自の専門知識を活かしてこれを上回ることが可能なはずです。
- LLM はいまだに高コストで計算負荷が高く、小規模なチームで拡張が制限されます。
- 人間の創造力は依然として不可欠です。LLM はコード生成や画像生成などのタスクをサポートしましたが、プロジェクトの方向性を先導する直観性に欠けていました。鍵となる質問、分析の選択肢、意味を持つ視覚化は、データ サイエンティストが実行しました。AI は支援することはできても、プロジェクト全体を見通せる独自の観点や創造的なインサイトは持ち合わせていません。
これらの調査結果は、LLM は強力なツールではあるものの、専門家の代わりになるものではないという見解を強めるものです。
Microsoft Copilot を最適化するための推奨事項
ブラウザーベースの言語モデルと複数の Copilot プラットフォームにわたる実践的な調査により、Microsoft Copilot のパフォーマンスと使いやすさを財務アプリ向けに最適化できる機会を特定しました。
最適化の機会 1 – パフォーマンスを透明化する: タスク処理が LLM から TextBlob などのシンプルなツールにオフロードされる際に、その情報をユーザーに明示的かつリアルタイムに提供します。制限や再ルーティングについて説明するインターフェイスのキューや要約のメッセージなどを表示して、ユーザーがそれに従い期待値やワークフローを調整できるようにします。また、担当者が特定の NLP タスクに使うツールを自信を持って選択できるように、各モデルのパフォーマンスの違いを明確に伝える必要があります。
最適化の機会 2 – CSV の使いやすさを向上する: 分析の精度を損なうことなく、ユーザーが構造化されたコンテンツを貼り付けまたはアップロードできるようにして、CSV や表形式の入力のネイティブ処理を実行しやすくします。正確な結果を出力するには、多くの場合、構造化された情報を手動でプレーン テキストに変換する必要がありました。これを解消すれば、データ量の多いワークフローでの Copilot の有用性を大幅に強化できます。
最適化の機会 3 – 基本的な NLP タスクのハルシネーションを削減する: センチメントの分類といった重要な分析の出力を確実に行い、書式設定や変換の段階で精度を維持し、破損しないようにして、シンプルな NLP 機能の信頼性を高めることを重視します。これにより基本の出力への信頼性を高め、Copilot の高度な機能の価値を維持できます。
まとめ
金融・財務関連の言葉には、戦略、曖昧な表現、ニュアンスが折り重なっていることから、センチメント分析ツールにとってはストレス テストになるものです。この調査では、LLM は財務センチメントの検知で従来の NLP ライブラリのパフォーマンスを上回ったものの、大規模に導入するには依然として構造面、経済面、信頼面で障壁があることが明らかになりました。
ただし、慎重に使用すれば、特に事業部門レベルでは、従来の分析を補完するパターンや変化の特定に LLM が役立つ可能性があります。マイクロソフトの決算説明会のケース スタディでは、事業部門別に分類しモデルを強化したアプローチが、経営幹部のトーンと投資家の行動を結び付ける強力な方法になる可能性が示されました。
Microsoft Copilot のようなツールは計り知れない可能性を秘めていますが、今後それを引き出すには、LLM 機能とのより緊密な統合、透明性の向上、企業ニーズへのさらなる注視が必要になります。
LLM は、人間の専門家の代わりになるのではなく、新しい強力なツールセットを提供し、人間の知能と組み合わさることで、財務分析の未来を再形成することになるでしょう。
注: ChatGPT は OpenAI によって開発され、マイクロソフトの Azure スーパーコンピューティング インフラストラクチャで動作します。マイクロソフトと OpenAI は AI サービスの開発と提供において提携していますが、OpenAI は独立した組織です。Azure OpenAI Service は、OpenAI モデルへのエンタープライズ クラスのアクセスを提供します。
Join the conversation