
バイブコーディングを活用した NPU アプリ開発
※本ブログは、米国時間 3 月 4 日に公開された “Vibe Coding for the NPU” の抄訳です。
Copilot+ PC でオンデバイス AI アプリを構築する方法
Copilot+ PC を購入したばかりで、NPU で一体何ができるのか知りたいという方は、ぜひこの記事をお読みください。また、多数の Copilot+ PC を管理しており、ワークロードの割り当てについてガイドがほしいという方にもお勧めします。
今後は、必ずしもクラウドをメインに使う必要はありません。今や、NPU (ニューラル プロセッシング ユニット) が現実的に広く利用される開発ターゲットであり、最先端の AI ワークロードをデバイス上で直接実行できるようになっています。これにより、PC に搭載されているローカルのハードウェアを使用して、結果を迅速に得る、レイテンシを抑える、さらにはオフラインや機内モードで作業するといったメリットが得られます。NPU 向けの開発を始めるのは、おそらく皆さんが想像している以上に簡単です。
Foundry Local は、localhost の OpenAI 互換エンドポイントを通じて、モデルとして動作します。このため、OpenAI SDK を使用している方なら、既に NPU 向けの開発方法を知っていると言えます。これに AI を利用したコーディングを組み合わせれば、プロの開発者としての技術は必要ありません。何をしたいかを具体的に伝えるだけでよいのです。
私は Surface のマーケティングを担当しています。Charles Petzold 氏が「Programming Window」を出版したころ以来、私は日常的な開発業務には関わっていません。”Hello world” プログラムを書くのに 90 行の C 言語コードと WndProc コールバックが必要だった、あの時代です。私はキャリアの早い段階ですぐに、自分よりも才能に恵まれた開発者が周りにいることに気付きました。一方で、ハードウェア ソリューションを組み合わせて、それで何ができるか説明することを得意としていました。しかし今では、バイブコーディングのおかげで、自分とは相性が悪かった分野が強みとなりました。「これはバイブコーディングで対応できるんじゃないか?」と思ったことは、実際にできるのです。
実際に AI コーディング アシスタントを使用して、搭載したい機能を説明し、4 つのタブと 5 つの AI タスクを備えたオンデバイスで動作する AI アプリケーションを作成してみました。この記事では、その工程の中で学んだことを詳細に説明します。プラットフォーム、ツール、ワークフローのほか、実際にハードウェア上でプログラムを構築してみて初めてわかった現実的な考慮事項について見ていきましょう。
前置きが不要な方はこちらのリンクをご活用ください。
- 実際に動作するアプリをすぐに作ってみたい → 初めての NPU アプリを数分で作成
- モデル選択の妥当性を検証したい → AI Toolkit のモデル カタログ
- 混在環境に展開したい → クロスプラットフォーム開発 + 運用化
- 画像認識機能を使いたい → Phi Silica
- 実際に作成されたものを見てみたい → Surface NPU デモ アプリ
この機能はなぜ重要なのでしょうか? それには、可用性、経済性、データ主権の 3 つが大きく関わります。詳しく見ていきましょう。
NPU 向けに開発する理由
長年にわたり、非常に負荷が大きいとされる AI ワークロードはクラウドで処理されてきました。最先端の推論機能、複雑なエージェント チェーン、高度な処理といった場合は、クラウドにメリットがあります。しかし現在では、実際にやりたいことの大半が、ローカルで実行されるモデルでも十分に対応できるようになっています。ここで言う「ローカル」とは、ユーザーの鞄の中に入っているデバイス、つまり、電車の中や取引先のロビー、勤務先で使用されている Surface のことです。サーバーや VM のことではありません。AI 専用チップを搭載した、実際にエンドポイントとなるマシンを指しています。
可用性: NPU を使用するワークフローであれば、機内モードに設定している場合やクリーンルーム内、工場の現場、電波が届かない調査現場などでも実行でき、ネットワーク接続は必要ありません。AI がデバイス上に備わっているため、ユーザーはどのような場所にも持ち込んで使用できます。
経済性: NPU による推論の場合、一度ハードウェアを購入してしまえば、実行するたびにコストがかかることはありません。トークン単位の API 使用料、データ転送料、従量課金制のコンピューティング料金は不要です。私はこれを 80/20 の計画モデルに沿ったものと考えています。日常的な AI タスクのほとんどは追加コストなしで実行することが可能であり、最先端の推論機能がどうしても必要なタスクにのみ、クラウドで実行される有料の推論機能を使用するという考え方です。
データ主権: データはクラウドへ転送されることなく、ローカルの NPU で処理されるため、国境を越えたデータ転送を減らすことができます。どのような展開環境であっても、エンドポイント管理、デバイスのアクセス制御、適用される現地法といった環境独自の法規制や運用上の要件を評価する必要があります。そうした規制のある環境では、オンデバイス AI が広範なコンプライアンスおよびデータ ガバナンス戦略において有力な要素となり得ます。ただし、それによって法務面、契約面、セキュリティ面の適切な管理が不要になるわけではありません。
バイブコーディングとは
これは業界で AI 拡張開発と呼ばれる手法です。インターネット上ではバイブコーディングと呼ばれますが、どちらも同じ意味です。ユーザーが何をしたいかを説明すると、AI コーディング アシスタントがコードを書き、それをユーザーが実行して問題のある箇所を伝え、AI が修正します。このような手順を繰り返し行います。ユーザーがアーキテクトと QA エンジニアの役割を担い、AI が実装を担当するという構図です。
例としては、GitHub Copilot CLI (英語) や Cursor といった各種 AI コーディング アシスタントが挙げられます。どのツールを使用するかよりも、ワークフローのほうが重要です。ユーザーが機能を説明し、AI アシスタントがコードを書き、それをユーザーが実行してうまく行った点と問題点を伝え、AI が修正します。AI は、Flask によるルーティング、CSS レイアウト、正規表現、JavaScript のイベント ハンドラーといった定型的なコードを扱います。一方で、ユーザーはアーキテクチャの決定、実機テスト、製品の評価を担当します。
なぜこれが NPU 向けの開発において特に重要となるのでしょうか? それは、AI コーディング アシスタントが OpenAI SDK のパターンを熟知しており、Foundry Local が互換性のある API を使用しているからです。「互換性がある」とは、標準の SDK がチャット内容の補完や使用頻度の高い推論パターンで動作することを意味しますが、モデル ID やストリーミングの挙動に軽微な違いが見られることがあります。マイクロソフトはこれを「OpenAI 互換の SDK および HTTP クライアント」としてドキュメントにまとめています。実際に、この記事で扱っているワークロードでは SDK をそのまま使用できます。参入障壁は以前より大幅に下がり、ワークフローを説明するだけで NPU 向けのコーディングを始めることができるようになりました。
開発の始まり: 試行段階から実用的なアプリへ
ここからは IT のプロとしてレッスンを開始します。まずはモデルを検証し、それからコーディングに移ります。計画の作成から始めるのではありません。マウスのクリックから始まります。
VS Code を開いて、AI Toolkit 拡張機能をインストールし、モデル カタログを確認します。デバイスには既に Phi Silica というモデルが存在します。これを Playground に読み込んでメッセージを入力すると、応答が返ってきます。すべてオンデバイスで処理され、API キーもクラウド エンドポイントも必要ありません。VS Code 内で NPU がそのまま推論を実行するだけです。
ここで、LM Studio を使用したときに、ローカル モデルがポートで動作していたことを思い出しました。もし Foundry Local も同様のしくみなら、同じようにそのポートにアクセスする Web アプリを作成できるのでしょうか?
そこで GitHub Copilot CLI を開いて、やりたいことを説明してみます。
「Surface 上に、Foundry Local 経由で実行されるローカルの AI モデルがあります。このモデルではローカル ポートで互換性のある API が公開されています。これに接続してチャット インターフェイスとして動作する Flask Web アプリを作成してください」
しばらく待つと、Copilot が実際に動作する Flask アプリを生成してくれました。これを実行してみると、ローカル モデルに接続されます。完全に NPU で実行されている AI と、Web ブラウザーを介してチャットすることができました。クラウドも API キーもサブスクリプションも使っていません。これは驚きです。
そしてここからは、バイブコーディングのループが始まります。それぞれの手順で、次にやりたいことを説明するだけです。タブにサイドバーを付け、ローカルの予定表データから毎日のブリーフィングを取得し、ローカルとクラウドのどちらでワークロードを実行するかを決定する 2 系統ルーターを作り、最後に音声、カメラ、ペンによる注釈の書き込み、翻訳の機能を備えたフル機能の現場検査ワークフローを作成します。
GitHub Copilot CLI に移行してからは、何度もコピー アンド ペーストを繰り返さなくても、デバイスにコードベース全体を読み込んで編集できるようになり、その速さを実感しました。この瞬間、ちょっとしたデモ アプリから、本格的なアーキテクチャを備えた正真正銘のマルチタブ アプリケーションへと進化したのです。先日の Hard Fork ポッドキャストで、Kevin Roose 氏と Casey Newton 氏が、AI コーディング ツールの飛躍的な進化を ChatGPT 黎明期の動きと比較していたのですが、それをリアルタイムで体験した私としては、まさにそのとおりだと感じました (Hard Fork を聴いたことがない方は、ぜひ聴いてみてください)。
Python、HTML、CSS、JavaScript を使用し、開発の大部分を AI コーディング アシスタントとの対話で進めました。作成したのは、C 言語で WndProc コールバックを書いていたころ以来、日常的な開発業務から離れていたマーケティング担当者です。
最初の一歩: AI Toolkit のモデル カタログ
コードを書く前に、まずは AI Toolkit for VS Code を確認します。ここでは Model Catalog と Playground の 2 つが重要となります。
Model Catalog を開き、ローカルの NPU での実行に最適化されたモデルを絞り込みます。
| モデル | パラメーター | 強み | NPU 対応状況 |
| Phi-4 Mini | 38 億 | 一般的なテキスト: 要約、抽出、生成、翻訳 | Intel (OpenVINO)、Qualcomm (QNN) |
| Phi Silica | 非公開 | Copilot+ PC におけるオンデバイスでの言語およびマルチモーダル処理 | Intel および Qualcomm (Windows AI API) |
| Qwen 2.5 | 70 億 | 一般的なテキスト: 大規模コンテキスト、強力な推論 | Qualcomm (QNN)、GPU フォールバック対応 |
| その他のモデル | モデルによって異なる | カタログには NPU に最適化された新たなモデルが追加されます。定期的にご確認ください。 | チップによって異なる |
ローカル モデルをすべて確認したい方は、Windows 上の Microsoft Foundry ですぐに使用できるローカル LLM および Windows AI の概要ページのデシジョン ツリーをご覧ください。
Playground は、ユーザーが自身で検証を行うためのサンドボックスです。モデルを選択して読み込み、VS Code 内で直接チャットしながら開発を進めます。プロンプトのテストやレイテンシの実験、コンテキストの制限などを、アプリケーション コードを書く前から試すことができます。また、私たちが知る限りでは、Phi Silica で初期モデルをダウンロードして準備する場合に最も信頼できる方法でもあります。
プラットフォーム要件
ハードウェア
任意の NPU 搭載 Copilot+ PC を使用します。現在、Surface の一般ユーザー向け Copilot+ PC には Snapdragon X が搭載されており、Surface の法人ユーザー向け (業務用) Copilot+ PC では Snapdragon X と Intel Core Ultra のモデルを選べます。
| 搭載チップ | NPU | Surface デバイスの例 |
| Intel Core Ultra (Lunar Lake) | Intel AI Boost、OpenVINO ランタイム | 法人向け Surface Laptop と法人向け Surface Pro (コマーシャル) |
| Qualcomm Snapdragon X (Elite/Plus) | Hexagon NPU、QNN ランタイム | Surface Laptop、Surface Pro (コンシューマ)、法人向け Surface Laptop、法人向け Surface Pro (コマーシャル) |
ソフトウェア スタック
範囲この記事で取り扱うのは Windows 版のみです。ここで取り上げる Foundry Local、AI Toolkit、NPU ランタイムは、Windows 11 搭載の Copilot+ PC ハードウェア (Intel Core Ultra または Qualcomm Snapdragon X) が要件となっています。
Foundry Local についての注意事項: Foundry Local は現在パブリック プレビューとして提供中です。SLA はなく、下位互換性も保証されていません。リリースごとに内容が変更される可能性があるため、広範囲に展開する前にリング方式で段階的に検証を行ってください。最新情報は Foundry Local のドキュメント ハブでご覧いただけます。
| コンポーネント | インストール | 参考情報 |
| Windows 11 24H2+ | Windows Update | Windows AI API |
| Foundry Local (プレビュー) | winget install Microsoft.FoundryLocal | Foundry Local の使用を開始する |
| Python 3.10 以降 | winget install Python.Python.3.11 | |
| foundry-local-sdk | pip install foundry-local-sdk | SDK リファレンス |
| OpenAI Python SDK | pip install openai | SDK 統合ガイド |
| Flask | pip install flask | |
| VS Code + AI Toolkit | VS Code マーケットプレース | AI Toolkit の概要 |
⚠️ パッケージ名に関する警告: foundry-local-sdk (マイクロソフト公式 SDK) をインストールしてください。PyPI の類似した名前のパッケージと混同しないように注意しましょう。本記事の執筆時点で、foundry-local (v0.0.1) は公式 SDK ではなく、エラーが発生する (または予想外の動きをする) 可能性があります。Microsoft の SDK ドキュメントおよび PyPI (英語) を確認してください。
初めての NPU アプリを数分で作成
公式のクイックスタート ガイドは「Foundry Local の使用を開始する」でご覧いただけます。以下では、その補足としてバイブ コーディングのワークフローをご紹介します。
ステップ 1: ランタイムをインストールする
winget install Microsoft.FoundryLocal
pip install foundry-local-sdk openai flask
ステップ 2: AI コーディング アシスタントにプロンプトを入力する
「localhost:5000 でチャット インターフェイスとして動作する Flask アプリを作成してください。バックエンドにはローカルの Foundry Local ランタイムで指定した OpenAI Python SDK を使用します。エンドポイントの URL を動的に取得するため、foundry-local-sdk を使用します (ポートをハードコードしないようにします)。モデルのエイリアスは ‘phi-4-mini’ とします。HTML を埋め込んだ単一ファイルのアプリとして作成してください」
アシスタントは、この要望に近い以下のようなコードを生成します。
from flask import Flask, request, jsonify from openai import OpenAI from foundry_local import FoundryLocalManager# Start Foundry Local and discover the endpoint dynamically manager = FoundryLocalManager("phi-4-mini") client = OpenAI(base_url=manager.endpoint, api_key=manager.api_key) model_id = manager.get_model_info("phi-4-mini").id app = Flask(__name__) @app.route("/chat", methods=["POST"]) def chat(): user_msg = request.json["message"] response = client.chat.completions.create( model=model_id, messages=[ {"role": "system", "content": "You are a helpful assistant."}, {"role": "user", "content": user_msg} ], max_tokens=512 ) return jsonify({"reply": response.choices[0].message.content}) if __name__ == "__main__": app.run(host="127.0.0.1", port=5000, debug=True)
ここで重要なのが base_url=manager.endpoint という行です。localhost:5272 のように特定のポートをハードコードしないようにします。Foundry Local は、サービスを起動するたびにポートを動的に割り当てます。SDK のエンドポイント検出を常時使用するか、または foundry-local-sdk を使用してアクティブなエンドポイントを自動的に取得します。詳細については Foundry Local SDK リファレンスを参照してください。
ステップ 3: 実行する
python app.py
# First run downloads the model (~3 GB). Subsequent starts are near-instant.
# Open http://localhost:5000最初にモデルをダウンロードするときにはネットワーク接続が必要です。その後はモデルがローカルにキャッシュされるため、完全にオフラインの状態で起動して使用することができます。ただし、ランタイムやモデルが更新されたりフローが修正されたりすると、場合によってはダウンロードが必要になることもあります。キャッシュ管理の詳細については Foundry Local CLI リファレンスを参照してください。
ステップ 4: 反復する
AI に機能を説明し、AI コーディング アシスタントがそれを実装するという手順を繰り返します。ユーザーは実機でテストを行い、AI アシスタントが自力で見つけることができなかった不具合について、「NPU でここがうまくいかなかった」とフィードバックを与えます。実機テストをループに組み込むことが重要です。一気にすべてを備えたアプリケーションを作るのではなく、機能を 1 つずつ作成してはテストし、次に進むようにします。
クロスプラットフォーム開発: Intel と Qualcomm
Foundry Local は、エイリアス システムを利用して、チップのシリーズに応じてモデルを自動的に選択します。ほとんどの開発者や、単一デバイスでの利用の場合、コードベースを 1 つ作成するだけで問題なく動作します。以下では、複数種類のデバイスが混在する企業環境に展開する場合の、プラットフォームごとの最適化について説明します。
エミュレーション環境でのアーキテクチャ検出
ARM 版 Windows では、platform.machine() を使用すると Python x64 は AMD64 と報告します。Python と PROCESSOR_ARCHITECTURE のどちらも、エミュレーション環境では誤った値を返します。正しいアーキテクチャを取得するには、WMI を使用してください。
result = subprocess.run(
["powershell", "-NoProfile", "-Command",
"(Get-CimInstance Win32_Processor).Name"],
capture_output=True, text=True, timeout=5,
)
cpu = result.stdout.strip().lower()
if "qualcomm" in cpu or "snapdragon" in cpu:
return "qualcomm"Snapdragon デバイスでは、可能な限りネイティブのARM64 Python を使用しましょう。これにより、パフォーマンスを向上させ、エミュレーションの不具合を抑制できます。
注意事項: Snapdragon では ARM64 Python を優先的に使用し、できるだけ x64 エミュレーションは避けてください。
チップによるモデルの互換性の違い
プレビュー版ランタイムでテストした際に見られた挙動です (2026 年 2 月)。今後 Foundry Local やドライバーが更新されると結果が変わる可能性があります。
| モデル | Intel (OpenVINO NPU) | Qualcomm (QNN NPU) | GPU フォールバック |
| Phi-4 Mini 3.8B | ✅安定 | ⏳開発中の NPU バリアント | ✅両方 |
| Phi-3.5 Mini | ✅安定 | ✅ NPU (Foundry 0.8.119+) | ✅両方 |
| Qwen 2.5 7B | ✅安定 | ✅安定 | ✅両方 |
| Phi Silica (テキスト + 画像認識) | ✅NPU | ✅NPU | なし (Windows AI) |
Foundry Local はエイリアスに従ってバリアントを選択します。phi-4-mini を要求すると、入手できる範囲でハードウェアに最適なビルドを取得します。NPU 実行プロバイダー全体で利用可能なモデルは、Foundry Local が新たにリリースされるたびに拡大しています。現時点では、Qualcomm でツールを呼び出すワークロードの場合、Qwen 2.5 7B が NPU アクセラレーションに完全対応し、本番環境にも対応しています。検出とモデルのルーティングは AI コーディング アシスタントが自動的に行います。
ランタイムのライフサイクルの違い
if SILICON == "qualcomm":
# Skip warmup - QNN is unstable with rapid reconnection attempts
print("Skipping warmup on Qualcomm (first request will load model)...")
else:
# Intel: warmup + keepalive for consistent latency
warmup_model()
start_keepalive_thread(interval=180)Intel の場合は、ウォームアップを行い、3 分ごとに keepalive ping を打つことが推奨されます。Qualcomm の場合は逆で、ウォームアップを行うと QNN ランタイムが不安定になります。最初に実行する要求でモデルの読み込みをトリガーするようにしてください。どちらのプラットフォームでも、自動再接続を積極的に使用しましょう。これはプレビュー版ランタイムの観測に基づいており、今後改善される可能性があります。
NPU から GPU へのフォールバック チェーン
try:
manager = FoundryLocalManager("phi-4-mini") # NPU first
except Exception:
try:
from foundry_local.api import DeviceType
manager = FoundryLocalManager("phi-4-mini", device=DeviceType.GPU)
except Exception:
# ⚠️ NOT RECOMMENDED FOR PRODUCTION - last resort only.
# The port is dynamic; this may break if the service restarts.
client = OpenAI(
base_url="http://localhost:5272/v1",
api_key="not-needed"
)トラブルシューティングの詳細については、Foundry Local のベスト プラクティスをご覧ください。
トークン量の制約に応じた設計
これはすべてに関わってくる制約です。コンテキストの上限はモデルによって異なります。Phi Silica の場合は約 4,000 トークンです。Phi-4 Mini はさらに多くのコンテキストを扱えますが、レイテンシとコストの関係で、実際に使用できるトークン量には制約が生じます。構造化フィールド抽出では約 1,884 トークン、ドキュメント分類では約 500 トークン、朝のブリーフィングでは約 2,200 トークンが観測されました。
設計原則: 1 つの機能をうまく実行する単一機能に特化したエンドポイントを作成しましょう。「1 つのチャットボットですべてをこなす」のではなく、/extract-fields、/classify-doc、/summarize といったエンドポイントを作成するようにします。1 つの呼び出し、1 つのジョブで、1 つの明確な応答を得るように心がけます。
正直に言うと、この制約によってアーキテクチャが洗練されるという効果もあります。すべての AI タスクに最先端モデルが必要なわけではありません。タスクのほとんどは大したものではなく、要約、抽出、分類といった単一目的のものです。これには 80/20 の計画モデルがそのまま当てはまります。つまり、GPT-4 を必要としない 80% のタスクを NPU が処理するということです。
Phi Silica: オンデバイスでの画像認識
初めて作成するアプリに画像認識機能を搭載しない場合は、このセクションはスキップしてかまいません。まずは Foundry Local と Phi-4 Mini の組み合わせから始めましょう。オンデバイスでの画像分類が必要になったら、こちらに戻ってきてください。
Phi Silica のセットアップ手順は Foundry Local よりもいくつか多くなりますが、クラウドに依存しないワークフローとしては最高レベルのオンデバイス画像認識機能が得られます。Phi Silica はマイクロソフトのオンデバイス モデルで、Windows AI API を通じてアクセスできます。オンデバイスでの言語およびマルチモーダルの用途に対応しており、Copilot+ PC で使用することができます。詳細な手順については、Phi Silica の使用を開始するおよび Phi Silica のチュートリアルのページをご覧ください。
Foundry Local (標準 REST API) とは異なり、Phi Silica は Windows API です。利用するには、systemAIModels の制限付き機能を含む MSIX (マイクロソフトの最新アプリ パッケージ フォーマット) でパッケージ化されている必要があるほか、パッケージ ファミリ名に関連付けられた LAF (限定アクセス機能) トークンと、オンデバイスでのモデルのプロビジョニングが求められます。開発ビルドでは LAF の強制適用が緩和される場合もありますが、本番環境への展開では常に有効なトークンが必要であると考えてください。LAF の詳細については Windows AI API のトラブルシューティングをご覧ください。
最低限の実行要件チェックリスト
- ☐ systemAIModels の制限付き機能を含む MSIX パッケージのアプリ
- ☐ オンデバイス対応の Phi Silica モデル (AI Toolkit Playground または AI Dev Gallery)
- ☐ 画像認識 API を呼び出す前にアプリで GetReadyState() を使用して準備状態をチェックする
- ☐ マイクロソフトが発行した LAF トークン
- ☐ フォールバックを検出するための正常性エンドポイント
機能を付加するパターン
アプリ全体に MSIX をパッケージ化するのではなく、小規模な C# ASP.NET Core サービスに複雑な Windows API をカプセル化します。
Flask app (localhost:5000) → Vision Service (localhost:5100) → Phi Silica on NPU
↑
MSIX packaged, LAF token,画像認識サービスは /health、/classify、/describe、/extract-text を表示します。メイン アプリは標準の Python Web アプリケーションのままです。
3 階層のフォールバック パターン
この記事全体で掲げる、アーキテクチャに関する 1 つの原則を挙げるとすれば、それは「アプリが黙ってエラーを起こすような事態を許してはいけない」ということです。モデルがフリーズしたり、ドライバーが更新されたりといったことは起こり得ます。そして時折、NPU がそれに対応しないことがあります。
| 階層 | 戦略 | 例: 写真の分類 |
| 階層 1 | 完全な AI パイプライン (推奨) | Phi Silica の画像認識機能が実際の画像を解析 |
| 階層 2 | 簡易的な AI アプローチ (機能は低下するが実用的) | Phi-4 Mini がファイル名から推測 |
| 階層 3 | 安全な既定値をハードコード (確実に動作) | 既知のシナリオに対する事前分類 |
このような階層を最初から組み込んでおきましょう。ほとんどコストをかけずに実装でき、何か問題があった場合はすべてを守ってくれます。
企業環境で NPU アプリを運用化する
Foundry Local はプレビュー期間中のため、フレームワークが進化するという前提で考えてください。混在環境への展開を考えている場合、これをあらかじめ計画に入れておかなければ、後から大きな問題になる可能性があります。
モデルの取得とオフライン対応: 初めて使用するときにはモデルをダウンロードしてローカル (通常は %LOCALAPPDATA%\.foundry\cache\models) にキャッシュします。キャッシュはユーザーごとに独立しているため、事前プロビジョニングはその前提で計画してください。
更新頻度: SLA はなく、下位互換性も保証されていません。テストはリング式に実施しましょう (開発 → パイロット → 広域展開)。ランタイム バージョンは固定します。Foundry Local や Windows が更新されたら、毎回再検証を行ってください。
ログ記録: 推論のレイテンシ、トークン数、使用されたフォールバック階層、モデルの読み込み時間を追跡します。ユーザー データや PII (個人情報) が含まれるプロンプトや応答をそのまま記録しないようにしましょう。
クラウド エスカレーション ポリシー: クラウドにルーティングする際の基準を明確かつ監査可能な形で設けましょう。ローカルでの実行を前提とし、クラウドでの実行は呼び出したときのみとします。デバイスからデータが送信されるときは毎回ログを記録します。機密性の高い環境では、管理者がクラウドへのエスカレーションを完全に禁止できるようにする切り替え機能を備えておきましょう。
セキュリティ: Foundry Local を localhost にバインドします。モデルのエンドポイントへのアクセスをローカル処理のみに制限し、明確なセキュリティ制御を経由せず外部インターフェイスにプロキシ接続されることがないように構成します。
パッケージ化: ランタイムは winget install Microsoft.FoundryLocal でインストールできます (Intune 互換)。マシン全体にインストールする場合は –scope machine と指定してください (Intune 互換)。ランタイム、事前にキャッシュされたモデル、作成したアプリケーションの 3 つのコンポーネントをステージングします。デモ リポジトリの setup.ps1 がそれぞれを検証します。
異種混在環境への対応: Intel と Qualcomm が混在する環境であれば、WMI 検出パターンと 3 階層フォールバック アーキテクチャが、オプションではなく必須となります。広範囲に展開する前に両方のチップ シリーズでテストしてください。
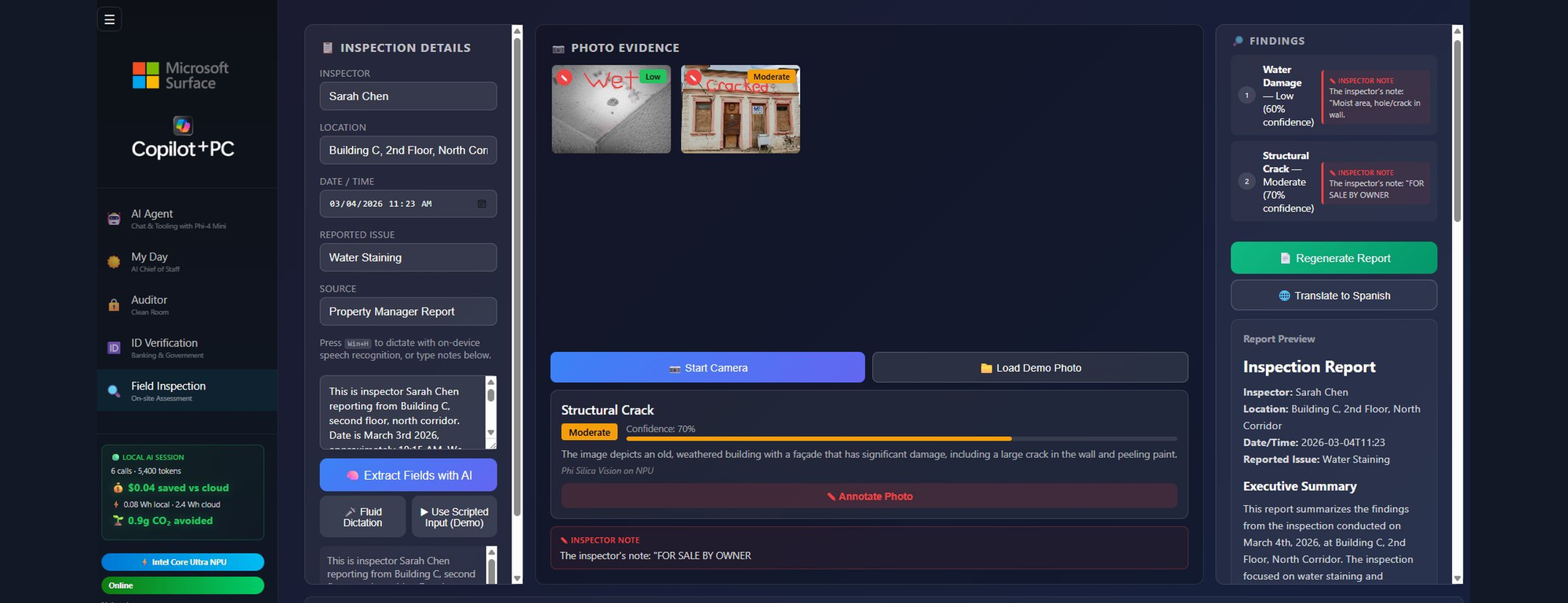
実際の成果物: Surface NPU デモ アプリ
4 つのタブを備え、5 つの AI タスクを実行し、クラウドへの呼び出しを一切行わないデモ アプリができました。これが、バイブコーディングで少しずつ成長させながら作り上げたアプリケーションです。 私はこのデモをパートナーの営業担当者、企業のお客様、社内のリーダーに向けて披露しました。その中で、毎回会話の流れが変わる瞬間がありました。機内モードに切り替えてもアプリが動作し続けるところを見せた瞬間です (それと、クラウド費用が 0 になっているトークン予算のダッシュボードを見せた瞬間も)。
機能の詳細
AI エージェント: Foundry Local を通じて Phi-4 Mini が駆動するローカルのチャット アシスタントを運用します。自然言語クエリ、ツールの呼び出し、構造化された応答などから始める方が多いでしょう。
My Day: ローカルの予定表、メール、タスク データを取得し、完全にオンデバイスで、朝のブリーフィングを構造化された形で生成します。
2 系統ルーター: 各要求を評価して、ローカルの NPU で対応できるか、それとも最先端のクラウド モデルにエスカレーションする必要があるかを判断します。判断のロジックをリアルタイムで提示し、デバイスからデータを送信する前にユーザーによる明示的な同意を求めます。
現場検査 Copilot: マルチモーダル対応のサンプルです。5 つの NPU 機能が 1 つのワークフローにまとめられています。
-
- 音声: 音声認識の出力を NPU が文字に起こして、構造化されたフィールド (位置、問題のタイプ、重大度) を抽出します。
-
- カメラ: 問題点を撮影した写真を Phi Silica がオンデバイスで分類します (水損、建造物のひび、カビ、機器の不具合など)。
-
- ペン: ローカルの手書き認識機能により Surface ペンで写真に注釈を書き込みます。
-
- レポート生成: NPU が音声、写真、注釈をまとめ、書式の整った検査レポートを作成します。
-
- 翻訳: 1 タップするだけでレポート全体を完全にオンデバイスでスペイン語へ翻訳します。
対象とするインダストリーには、建設、保険請求、公益事業、製造業の品質保証、不動産管理、OSHA 規格への対応などが挙げられます。こういった環境ではネットワーク接続が弱かったり、まったくなかったりすることが珍しくないため、オフライン機能が欠かせません。
ダッシュボードには各セッションの最後にデモ値が表示されます。ローカル AI タスク数は 5、クラウド呼び出し数は 0、消費トークン数は約 520、クラウド推論費用は 0.00 ドル、デバイス外への通信は 0 バイトとなっています。
コード: フォークして発展させる
github.com/frankcx1/surface-npu-demo (英語)
コードのクローンを作成して、setup.ps1 を実行し、http://localhost:5000 を開きます。するとチップが自動検出され、適切なモデルが選択されて、すぐに実行できるようになります。
コードをフォークし、ご自身の用途に合わせて発展させてください。業界のワークフローに応じてタブを追加したり、カタログから別のモデルを選んで取り換えたりすることも可能です。良いものができたら、プル リクエストの送信をお願いします。ぜひマージさせてください。それこそが活気あふれるプロジェクトのあるべき姿です。
得られた教訓
数か月にわたり、Intel と Qualcomm の両方のデバイスでアプリを構築した経験から、最初に知っておいたほうがよいことをお伝えします。
IT プロフェッショナル向け
-
- NPU は、サポートされているワークロードに対して、本番環境でも問題なく推論を実行できる性能を備えています。クラウドで行うと 1 回ごとに数円の料金が発生するようなタスク (公開されている Azure OpenAI の料金に基づく) でも、低消費電力でサステナブルに推論を実行できます。これが、大規模な混在環境でどれほどの効果につながるか考えてみてください。
-
- まずは AI Toolkit のモデル カタログから始めましょう。モデルの種類を確認し、Playground でテストを行い、制約について理解してから、本格的に使用しましょう。
-
- モデルの制約がアーキテクチャに影響します。Phi Silica は約 4,000 トークン、Phi-4 Mini はさらに多くのコンテキストを扱えますが、レイテンシとコストの関係で、実際に使用できるトークン量には制約が生じます。チャットボットではなく、機能を絞った単一タスク向けのエンドポイントを設計するようにしましょう。
-
- そのままではクロスプラットフォームにはなりません。Intel と Qualcomm では NPU の挙動が異なります。両方をテストし、WMI を使用して、フォールバック チェーンを構築します。
-
- Foundry Local はプレビュー中です。SLA はありません。リング方式で段階的に更新していきましょう。
-
- 機内モードで証明しましょう。Wi-Fi と5G 通信を切った状態でアプリを実行してみてください。このデモで必ず会話の流れが変わります。
バイブコーディングを行うユーザー向け
-
- まずは Foundry Local と OpenAI SDK の組み合わせから始めましょう。これが NPU での推論実行を学ぶ最短経路です。
-
- 必ず SDK エンドポイント検出を使用してください。base_url=manager.endpoint というステートメントを使います。ポートをハードコードしてはいけません。
-
- 実機テストを早い段階から頻繁に行いましょう。モデルがフリーズしたり、コンテキストがオーバーフローしたり、ドライバーが妙な挙動を見せたりといったことは、実機で動かしてみないとわかりません。
-
- すべてに対してハードコード フォールバックを用意します。手を抜かずプロ意識を持ちましょう。
オンデバイス NPU アプリが適さない用途
何を作るべきかと同様に、何を作るべきではないかを知っておくことも重要です。私の苦い経験をお伝えします。
-
- モデルのトレーニングには使用しない: NPU は推論アクセラレータです。
-
- 長時間にわたるエージェントのループ処理には適さない: 小規模モデルは一貫性を失いがちです。単一機能のエンドポイントを作成しましょう。
-
- 無制限の会話履歴の保持には使用しない: コンテキストが約 4,000 トークンに収まるよう整理してください。
-
- クラウドの機能に置き換わるものではない: 日常的に実行する大半のタスクをオンデバイスで処理できるため、クラウド分の予算を必要なタスクに回すことができます。
今すぐ使ってみる
# 1. Install the runtime
winget install Microsoft.FoundryLocal
# 2. Install Python dependencies
pip install foundry-local-sdk openai flask
# 3. Clone the demo
git clone https://github.com/frankcx1/surface-npu-demo.git
cd surface-npu-demo
.\setup.ps1
# 4. Run it
python npu_demo_flask.py
# Open http://localhost:5000
# 5. Or start from scratch with your AI coding assistant:
# "Build me a Flask app that uses Foundry Local to serve
# Phi-4 Mini on the NPU with an OpenAI-compatible API.
# Use the SDK for endpoint discovery. Single file, HTML inline,
# chat interface on localhost:5000."バイブコーディングを行うユーザー向けのヒント: この投稿の全文をコンテキストとして AI コーディング アシスタントに提示してみましょう。SDK パターン、注意点、フォールバック チェーンなどの内容が網羅されており、重要な情報源となります。
今週はワークロードを 1 つ選んでみましょう。PII スキャン、ドキュメント分類、受付フォームの抽出、契約の優先順位付けなど、どれでもかまいません。そして、機内モードにして NPU で実行し、レイテンシを測定して、これまでかかっていたクラウドでの推論実行費用と比較してみましょう。その後、実機で得られた実測データからビジネス ケースを構築します。
私は Silicon Graphics (SGI) でキャリアをスタートさせ、GPU がワイヤーフレームを描画するだけの時代から、業界全体を変革するに至るまで、その登場と進化を間近で見てきました。はるか遠くにあると思っていた未来が現実のものとなり、本当に驚きです。ハードウェアは盛衰を繰り返しながらも再び勢いを取り戻しており、AI 専用チップが次の大きな動きになりそうな予感がしています。私はこれまでに、Surface Hub などの製品を世に送り出すという貴重な経験をしてきました。ツールは変化するものですが、開発者の情熱は変わりません。以前と変わったのは、ユーザーが自分に合ったツールを使えるようになったことです。実用的なプログラムを作るために、必ずしもエンジニアになる必要はなくなりました。
まずは何かを作ってみましょう。良い成果が生まれることを願っています。
Microsoft Learn の参考資料
| トピック | リンク |
| Foundry Local の概要 | Foundry Local とは |
| Foundry Local のクイックスタート ガイド | Foundry Local の使用を開始する |
| SDK の統合 (Python、C#、JS) | 推論 SDK の統合 |
| Foundry Local のアーキテクチャ | アーキテクチャとコンポーネント |
| SDK リファレンス | Foundry Local SDK リファレンス |
| CLI リファレンス | Foundry Local CLI リファレンス |
| Windows AI API | Windows AI API とは |
| Phi Silica | Phi Silica の使用を開始する |
| Phi Silica のチュートリアル | Phi Silica 手順ガイド |
| Windows AI のトラブルシューティング | API のトラブルシューティング |
| AI Toolkit for VS Code | AI Toolkit の概要 |
| Windows AI のデシジョン ツリー | Windows でローカル AI を使用する |
| すぐに使用可能なローカル LLM | Windows 用ローカル LLM |
| Foundry Local の GitHub | microsoft/Foundry-Local (英語) |
Surface Copilot+ PC で構築してみましょう。リポジトリ: github.com/frankcx1/surface-npu-demo (英語)
Join the conversation