
Microsoft 365 Copilot の Researcher エージェント
※本ブログは、米国時間 3 月 26 日に公開された “Researcher agent in Microsoft 365 Copilot” の抄訳を基に掲載しています。
業務で Deep Research を利用するためのアシスタント
Gaurav Anand (Microsoft 365 エンジニアリング担当 CVP)
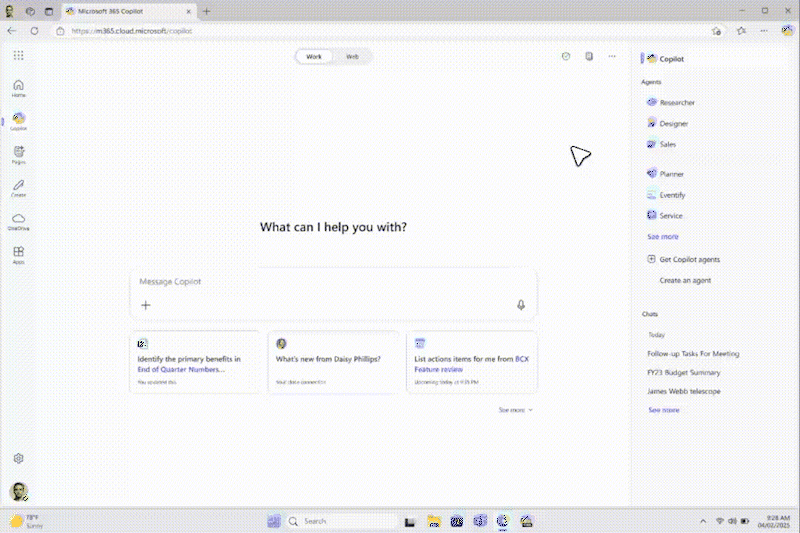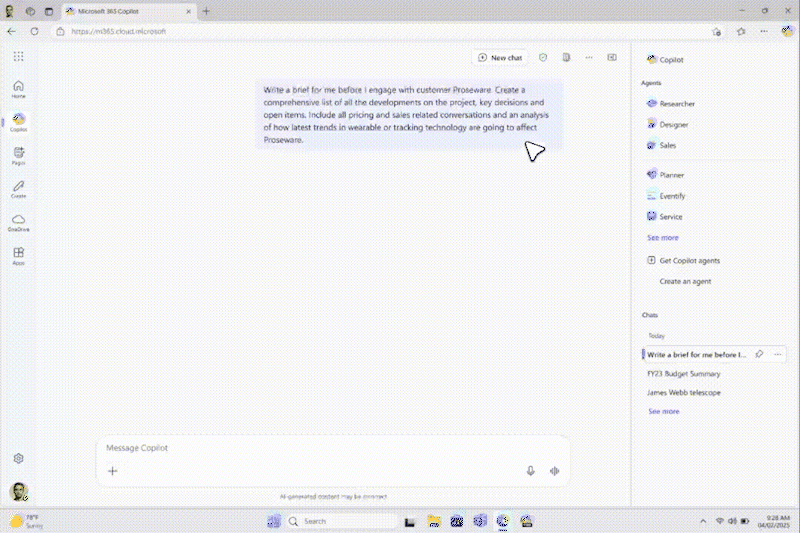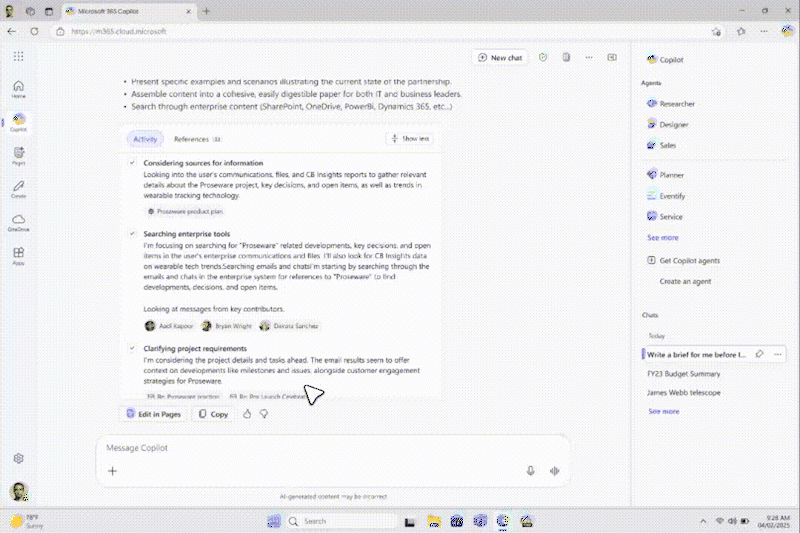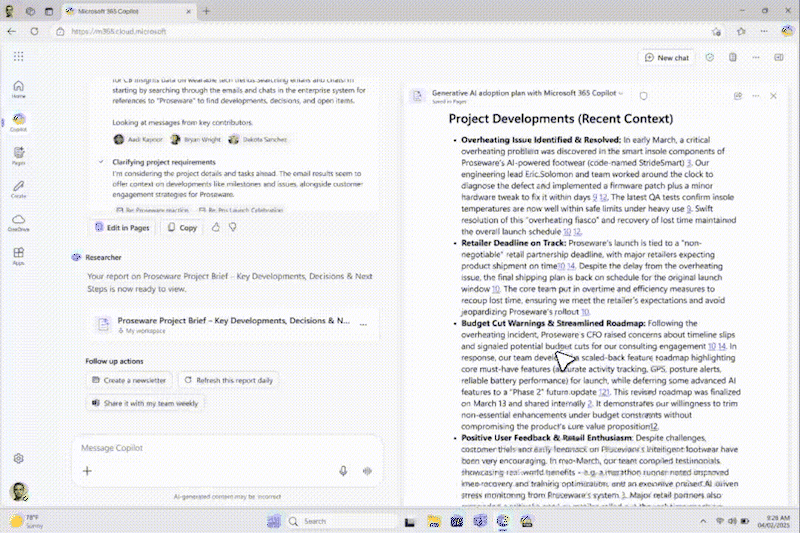
近年、推論モデルが進歩したことで、思考連鎖に基づく反復推論に変革がもたらされています。これにより、AI システムは膨大な量のデータを抽出して十分な根拠のある結論を導き出せるようになりました。Web を中心とする (AI) リサーチ ツールもいくつか登場していますが、現代のインフォメーション ワーカーが必要としているのは、企業データと Web データの両方に基づいて推論を行うモデルです。M365 ユーザーにとって、背景情報を十分に考慮した正確かつ詳細な調査レポートを作成することは非常に重要です。なぜなら、こうしたレポートは、市場参入戦略、販売提案、研究開発への投資などに影響を与える可能性があるからです。
Researcher エージェントはこのギャップに対処するため、メール、チャット、会議の録画、ドキュメント、ISV/LOB アプリケーションなどの企業データ ソースを探索して推論を実行します。このワークフローは、ほぼリアルタイムで答えを返す Microsoft 365 Copilot Chat よりも低速ですが、より詳細で正確な結果が得られるため、従業員の時間と労力の節約を実現できます。
マイクロソフトのアプローチ
マイクロソフトのアプローチは、人間があるテーマの調査を行う際の手順を再現するというものです。まず、明確にすべき事柄を探り、大まかな計画を考案し、問題をサブタスクに分割します。次に、それぞれのサブタスクについて推論→取得→レビューの反復ループを開始し、それ以上調査を続行しても新しい情報が得られないと思われるところまでメモ帳に調査結果を収集してから、最終レポートをまとめます。マイクロソフトは、構造化されたいくつもの段階のプロセスを使用して Researcher にこうした挙動を教え込みました。
初期計画段階 (P0)
エージェントは、ユーザーの発言と背景情報を分析して大まかな計画を立てます。このフェーズでは、エージェントがユーザーにタスクを明確にするための質問をすることで、最終的に内容と書式の両方の面でユーザーの期待に沿った出力結果を返せるようにします。このフェーズからのインサイトを I0 と定義します。
反復調査段階
次に、Researcher エージェントは、j = 1から始めて効果が減少し始めるまで反復サイクルをループします。
- 推論 (Rj): どのサブタスクに取り組むべきか、また不足している詳細情報は何かを特定するため、詳細な分析を行う
- 取得 (Tj): ドキュメント、メール、メッセージ、カレンダー、トランスクリプト、Web データを検索して、不足している詳細情報を取得する
- レビュー (Vj): 収集した証拠を評価し、ユーザーの元の発言との関連性を計算し、結果を「メモ帳」に保存する
ΔIj を、反復 j で Rj、Tj、Vj から取得した新たなインサイトと定義します。これらはその時点で既得の知識に追加されます (Ij = Ij-1 ∪ ΔIj)。
各サイクルで新たに得られるインサイト ΔIj は減少する傾向があります。エージェントがこれを監視し、ΔIm < ε となった場合に反復 m でそれ以上の調査を終了するためのチェックを実行します。
統合段階
エージェントは調査結果を集約し、パターンを分析し、結論を導き出し、一貫性のあるレポートの下書きを作成して、集計 Im を統合します。出力には説明が含まれ、追跡を可能にするために出典が引用されます。
Researcher エージェントの使用例
あるユーザーが「自社製品 P の第 4 四半期の成果は、業界のトレンドと比較してどうでしたか?」と質問したとします。この場合、次のように処理が始まります。
計画
サブタスクの特定: (1) 製品 P の第 4 四半期の売上数に関する社内データを取得する、(2) 第 4 四半期の傾向に関する業界ニュースまたはアナリスト レポートを探す
たとえば、特定の地域や競合他社が何に注目しているかなどを明確化するための質問をします。
反復調査
反復 1 は次のように行われます。
- 推論: 社内販売データを調査する
- 取得: 第 4 四半期の売上レポートを取得する
- レビュー: 製品 P の売上成長の促進における機能 F の貢献度を確認する
反復 2 は次のように行われます。
- 推論: 機能 F について調査するための計画を調整する
- 取得: F に関する社内外のやり取りを取得すると共に、Web 検索によって競合他社の製品に関する情報を収集する
- レビュー: F に関する顧客の評価や関連業界ニュースを取得する
反復サイクルごとにパズルのピースが集められ、これを繰り返すうちに、新たに取得されるのは細かい情報のみになっていきます。
統合
次に、Researcher がレポートの下書きを作成します。第 4 四半期における製品 P のパフォーマンスを市場の状況と徹底的に比較し、販売数に関する社内データと外部の業界分析を引用して、機能 F が競争上の差別化要因であったことを明確に示します。
技術的実装
現在の実装では、近日リリース予定の OpenAI o3 モデルのバージョンを搭載した OpenAI の Deep Research モデルを使用しています。このモデルは調査タスクに特化してトレーニングされています。パフォーマンス ベンチマークではその有効性が強調されており、Humanity’s Last Exam (HLEx) で 26.6% の精度を達成し、GAIA 推論ベンチマーク1 で平均スコア 72.6% を記録しています。
以下は、Researcher の構築において採用された技術的アプローチの一部です。
企業データの推論
モデルのツールキットを Copilot ツールで拡張しました。このツールは、会議、イベント、社内ドキュメントといったファーストパーティの企業データを取得するほか、グラフ コネクタを介して、公開されている企業 Wiki や統合 CRM システムなどのサードパーティのコンテンツも取得できます。これらのツールは、IT 管理者とセキュリティ専門家が Researcher の使用について保護、管理、分析できるようにする Copilot Control System の一部です。Copilot ツールは、モデルがトレーニングされた馴染みのあるインターフェイス (ドキュメントを「開く」機能やドキュメント内の情報を「スクロール」または「検索」する機能など) を使用してモデルに提供されます。
マイクロソフトは、Web と企業の調査クエリ間の本質的な違いによって生じる、モデルのオリジナルのトレーニング データの分布からの逸脱に対処するために、さまざまな手法を試してきました。社内評価によると、Researcher は通常、公開されている Web データを利用した場合のパフォーマンスと比較して、企業特有のクエリで同等の範囲に対応するためには、30~50% 多くの反復を必要とすることが明らかになっています。
企業特有の背景情報によるパーソナライズ
どのようなユーザーが行っても同じ結果になる Web 検索とは異なり、Researcher は高度にパーソナライズされた結果を生成します。エンタープライズ ナレッジ グラフを活用して、人、プロジェクト、製品に関する詳細や、これらの要素がユーザーの業務内でどのように作用し合うかといった、ユーザーと組織に関する背景情報を統合します。
たとえば、ユーザーが「Olympus について詳しく知りたい」と言うと、システムは Olympus が社内の AI プロジェクトであることを即座に特定し、ユーザーのチームがそのプロジェクトに基づいて業務を進める予定であることを理解します。背景情報が豊富に揃っていると、システムは次のようなことができるようになります。
- 「Olympus の基礎研究の側面に焦点を当てるべきですか、それとも統合の詳細の方がよいでしょうか」といった、より微細な点を明確にするための質問をする
- Deep Research モデルの開始条件 (P₀) を調整し、正確性を向上させるだけでなくパーソナライズも行うことで、企業固有の専門用語の理解度を上げる
詳細な推論を補完する詳細な検索
Researcher は、反復 Tj ごとに獲得するインサイトを増やすため、各クエリの広範な結果セットと、返された各ドキュメントの意味的な流れを取得します。
連続的に反復する手法ではなく、最初に各種のデータ ソース間で幅広く浅い検索を実行し、それに応じてモデルが特に注目すべき分野や要素を決定します。
専門エージェントの統合
企業の背景情報に沿ってデータを解釈するには、特定の分野における微妙な違いを深く理解した専門家の視点が必要になることがよくあります。それこそが、エージェントが Microsoft 365 Copilot エコシステムにおいて重要な役割を担っている理由です。
Researcher は、他のエージェントとシームレスに統合できるように拡張されています。たとえば、Sales エージェントを使用して高度な時系列モデリングを適用し、「製品 X がヨーロッパでの売上を牽引し、目標を 5% 上回ると予想されます」というようなインサイトを提供してくれます。
さらに、これらのツールとエージェントを連携させることも可能です。たとえば、ユーザーが「来週の顧客との会議に向けた準備を手伝ってください」と依頼すると、Researcher はまずカレンダーを検索して関連する顧客を特定します。次に最近のやり取りを検索し、さらに Sales エージェントから CRM の情報も取得します。
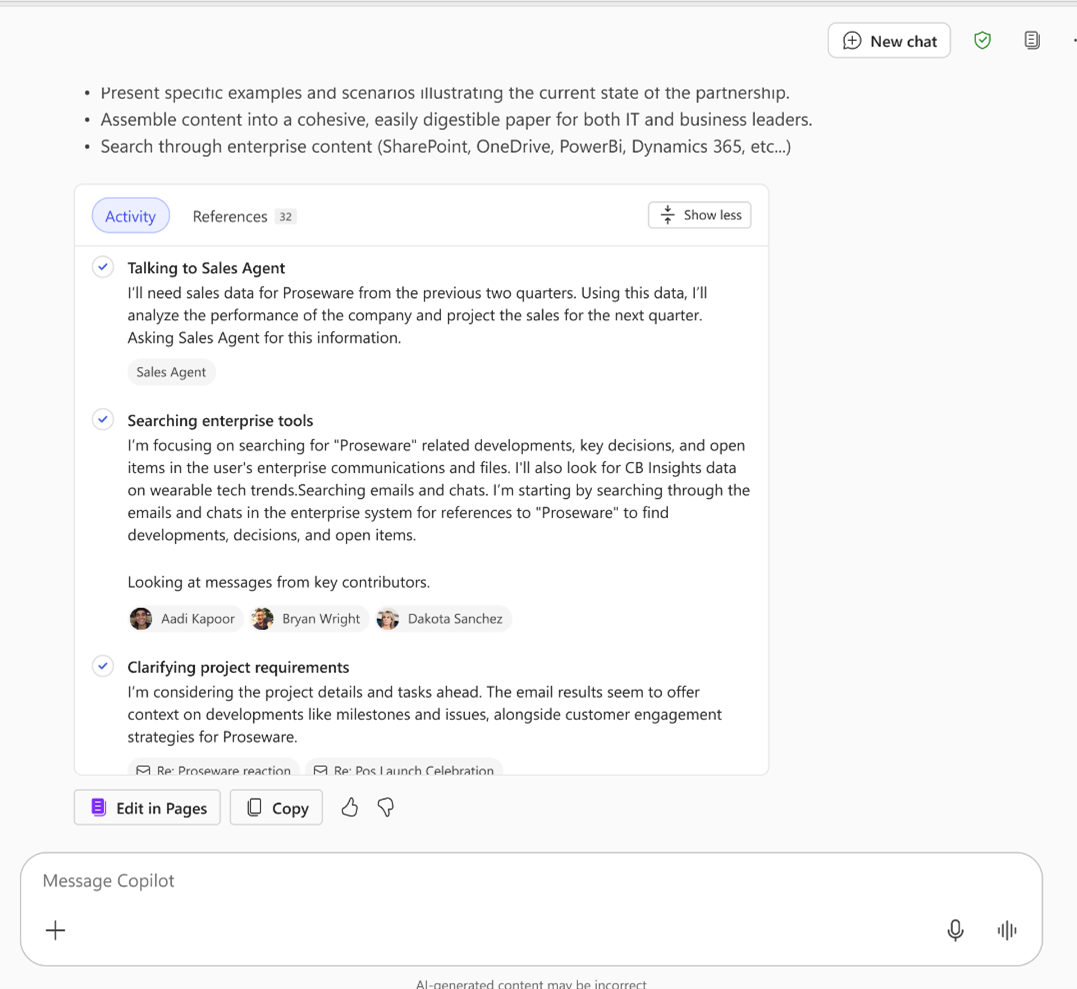
このように、Researcher が特定のタスクに特化したエージェントやツールに複雑なサブタスクを委任できるようにすることで、多段階推論の反復サイクルが 1 つのステップに圧縮され、Researcher エージェントのインテリジェンスを専門知識で補完できるようになります。
結果と影響
Researcher のメリットは、テストの初期段階から明らかになっていました。
回答の品質
初期のテストでは、複数のソースを参照する必要がある複雑なプロンプトに焦点を当て、広範囲にわたって Researcher を評価しました。品質評価には、各回答を次の 4 つの面から評価する ACRU と呼ばれるフレームワークを採用しました。
- Accuracy/正確性 (事実に基づき、正確か)
- Completeness/完全性 (すべての重要ポイントを網羅しているか)
- Relevance/関連性 (無関係な情報がなく、ユーザーのクエリに沿っているか)
- Usefulness/有用性 (タスク達成のために有用な回答か)
各項目について、人間と LLM ベースの評価者が 1 (非常に悪い) から 5 (非常に優れている) のスコアを付けます。
さまざまなクエリ 1,000 件で Researcher のパフォーマンスを基本機能のM365 Copilot Chat と比較したところ、正確性が 88.5%、完全性が 70.4%、関連性が 25.9%、有用性が 22.2% 向上しました。
また、事実関係を二重チェックする能力によってエージェントの正確性が向上したことは注目に値します。上記の評価において、エージェントは回答ごとに平均約 10.1 個のソースを引用しています。回答の 61.5% にはソースとして少なくとも 1 つの企業ドキュメントが含まれており、58.5% には Web ページが含まれ、55.4% にはメールが引用され、33.8% には会議の文字起こしデータが部分的に引用されています。
時間の節約
この測定では、次の 2 つの社内ユーザー グループを調査しました。
- 22 名のプロダクト マネージャー: 利害関係者との調整のために製品戦略ドキュメントとプロジェクトの更新情報を作成する
- 12 名のアカウント マネージャー: マイクロソフトの顧客とやり取りする、クライアントへの提案書を作成する、関係者との明確なコミュニケーションを維持する
どちらのグループからも、非常に前向きなフィードバックが得られました。調査対象者は、以前なら手作業で数日かかっていたタスクも、エージェントの支援を受けると数分で完了できるようになったと報告しています。全体として、Researcher を試験的に使用したユーザーの時間が 1 週間あたり 6 ~ 8 時間節約され、実質的に 1 日分の単純作業が不要になったと予想されます。
調査に参加したプロダクト マネージャーは次のように述べています。「私が確認していなかったアーカイブのデータまで見つかりました。AI が会議の文字起こしデータ、共有ファイル、Web などあらゆる場所を検索してくれるとわかったことで、最終的な推奨事項の信頼度が大幅に向上しました」。私は Researcher を毎日使用しています。Researcher のインテリジェンスが推論を実行することで点と点がつながり、魔法のような効果がもたらされます。以下は、会議に向けた準備のためのレポートからの抜粋です。

午前 11 時 30 分に「調査結果をチームに一斉に伝える」という仮の予定を設定していましたが、Researcher は私がその作業を既に済ませたことを確認し、その時間を使って代わりにチームからフィードバックを集めることを推奨しました。
今後について
強化学習
マイクロソフトは、レポートをより完全で正確かつ有用なものにするため、継続して Researcher の品質向上に努めます。企業データに適応する次の段階として、強化学習を使用し、現実世界の複数ステップの業務タスクに対するポストトレーニング推論モデルを作成する予定です。
これは、現在の状態 s に基づいて次のステップ a を選択するポリシー関数 (π(s)→a) を学習し、累積報酬を最大化することを目的としています。
- ステップ: モデルにアクセスできるアクションの範囲 (推論、ツール、統合)
- 状態: ユーザーの最初の発言とそれまでのインサイト In をカプセル化したもの
- 報酬関数: 各決定ポイントで出力の品質を評価する
形式的には、内部推論とアクションを交互に行い、累積的なインサイト I(i)=I(i-1)+R(si,ai) を構築します。ここで (R(si,ai)) は、状態 si に対してアクション a を実行することで得られる報酬を表します。連続的な反復を通じて、モデルは最適化されたポリシー ((π(s)) を学習します。
これを実現するため、マイクロソフトは質の高い調査レポート作成のためのデータセットの構築と、堅牢な評価指標やベンチマークへの投資に注力します。
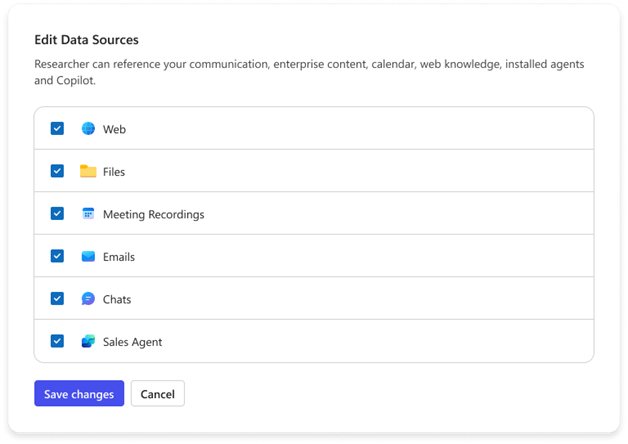
ユーザー コントロール
Researcher は、ユーザーがアクセスできるナレッジ ソースを徹底的に調べ、最も有用な情報を見つけ出します。しかし、マイクロソフトは、ユーザーや企業が情報ソースをより細かく制御する必要があるということを理解しています。そこで、Researcher ではレポートの作成元となるソースを「制御可能」にします。この機能がどのようなものになるかを示した初期イメージは以下のとおりです。
エージェント型オーケストレーション
エージェント型オーケストレーションは Researcher の中核となる機能です。すでに複数のマイクロソフト エージェントが統合されており、この機能を一般化する予定です。さらに、エンド ユーザーや管理者が独自のエージェントを Researcher ワークフローに組み込み、Researcher をカスタマイズできるようにします。
たとえば、法律事務所がレポートを弁論準備書面の形式にするためのエージェントを作成する場合、Researcher の出力をこのカスタム エージェントと連携させることで、出力をカスタマイズできます。
まとめ
Researcher は、ナレッジ ワーカーの日常業務を大きく変えることができるツールです。初期の結果によると、ユーザーはエージェントを信頼し、事実に基づいた正確で詳細なレポートを取得して、時間を節約し生産性を向上させています。マイクロソフトは、Researcher の機能をさらに拡張し、品質を向上させ、より細かくカスタマイズできるようにすることで、Researcher が業務に欠かせない信頼できるツールへと進化する未来を思い描いています。
Researcher のロールアウトやお客様への提供状況などの詳細については、M365 Copilot 内の推論エージェントなどを紹介したブログ記事を併せてご確認ください。
Join the conversation